
.png)
Notre article explique comment tirer parti du Vibe Coding tout en gardant contrôle, visibilité et qualité.
Nous suivre


J'en vois beaucoup qui se plaignent du VIBE Coding.
Oui c'est une technique nouvelle pour générer du code.
Oui, pour l’instant, nous n’avons pas la maîtrise complète du process.
Et oui, le code généré comme ça peut parfois être de très mauvaise qualité.
Le principal risque n'étant pas qu'il le soit... Parce que honnêtement, du code d'un junior, senior, lead peut aussi parfois être de mauvaise qualité, trop complexe ou pas assez testé.
La qualité du code a un cycle de vie.

Le vrai principal risque pour moi est que l'utilisateur de ce code n'en ai même pas conscience. Perso, j'ai réalisé ça moi même à l'époque.
Lorsque je génère du code en python ou en js, mes réactions sont opposés.
Vous voyez où je veux en venir ?
Un initié avec du vibe coding peut aller très loin. Il lui suffit de respecter les bonnes pratiques de code. Dans le cas opposé, l'illusion de maitrise est là jusqu'à ce que ça dérape.
On disait que la qualité du code avait un cycle de vie.
Et notre compréhension du code variait également avec le temps.
Plus la codebase s'agrandit, moins on est capable de comprendre toutes les implications de chaque ligne de code.
Et c'est cela qui crée le principal risque.
Le décalage entre ce qu'il y a dans le code et notre représentation mentale. Paul Graham le dit mieux que moi :
"Your code is your understanding of the problem you're exploring. So it's only when you have your code in your head that you really understand the problem."
Avec le vibe coding, on peut générer du code plus vite qu'on ne peut le digérer.
Et c'est là que tout commence à déraper.
Pour le réaliser, faites le test sur votre domaine d'expertise.
Utilisez un agent sur un problème que vous maîtrisez vraiment.
Au début, il s'en sortira bien. Mais plus votre contexte grandit, plus il commencera à prendre des libertés :
Exemple concret : Un test qu'il n'arrive pas à valider ? Il va tout simplement le supprimer ou le modifier pour afficher du beau 100% de réussite au rapport. Pratique, non ?
Une fois que le décalage commence, plusieurs mécanismes l'amplifient :
La dette de compréhension à intérêts composés
Comme la dette technique, elle s'accumule silencieusement.
Mais contrairement à la dette technique qu'on peut refactorer, la dette de compréhension vit dans nos têtes.
Et ses intérêts sont composés : plus on attend, plus c'est coûteux de rattraper.
Vitesse de génération > vitesse de compréhension
Un initié doit forcément être derrière du code vibecoder. Autrement, on navigue à l'aveugle en faisant confiance à une machine.
Et même pour un initié, il doit garder une vision globale continue sur le code généré.
Ça devient compliqué si on génère beaucoup trop de code trop vite.
Plus l'écart se creuse entre notre perception du code et la réalité du code, plus les risques grandissent exponentiellement.
La cascade d'incompréhensions
Chaque décision de l'AI basée sur une mauvaise compréhension crée de nouvelles couches d'erreurs.
Le code devient un château de cartes conceptuel.
Une hypothèse erronée au fichier A influence le module B, qui conditionne le service C...
Le vibe coding nous donne plusieurs illusions dangereuses :
L'illusion de productivité
On génère 10x plus de code. Est-on 10x plus productif ?
Pas vraiment. Le vrai coût se révèle au debugging, à la maintenance, à l'évolution.
On a juste déplacé le problème dans le temps.
L'illusion de contrôle
"Ça compile" ≠ "Je comprends"
"Ça marche" ≠ "C'est correct"
"Les tests passent" ≠ "C'est bien testé"
L'AI optimise pour faire passer vos critères visibles (compilation, tests, specs). Pas pour la qualité invisible (maintenabilité, robustesse, architecture).
L'illusion de maîtrise
On se sent aux commandes parce qu'on valide chaque suggestion. Mais valider superficiellement n'est pas comprendre profondément.
Souvenez-vous de mon exemple Python vs JS :
Et voilà le gros point qui dérange :
Le rôle de l'ingénieur évolue de l'authorship (écrire le code) vers l'accountability (être responsable du code).
Vous n'avez peut-être pas écrit chaque ligne, mais vous êtes toujours responsable de ce qui part en production.
Le problème ? On ne peut pas être sereinement responsable de ce qu'on ne comprend pas.
Qui est responsable du bug dans du code généré ?
C'est le piège : vous signez pour du code que vous n'avez pas écrit ET que vous ne maîtrisez pas.
Les vrais coûts du vibe coding mal maîtrisé sont cachés et différés : Le coût de réonboarding constant
Avec du code vibecoded non compris :
Le coût de maintenance explosive
Maintenir du code qu'on ne comprend pas, c'est comme réparer une voiture les yeux bandés. Chaque modification devient un pari.
Chaque refactoring devient un projet à risque.
Le coût de debugging d'un système opaque
Débugger du code qu'on n'a pas dans la tête, c'est un cauchemar.
On ne sait pas par où commencer.
On ne sait pas quelles hypothèses l'AI a faites.
On ne sait pas quels raccourcis ont été pris.
L'érosion du modèle mental
Plus le temps passe, plus notre représentation diverge de la réalité. Nos hypothèses deviennent obsolètes.
On prend des décisions basées sur une carte périmée du territoire.
La conclusion de tout ça ?
Le vibe coding n'est pas le problème.
Le problème, c'est le vibe coding sans compréhension.
Pour vibecoder sereinement, il faut rester au-dessus du seuil de compréhension. Et c'est exactement ce qu'on va voir dans la section suivante.

Maintenant qu'on a bien cerné les risques, parlons solutions.
Comment vibecoder sans finir avec une codebase incompréhensible et ingérable ?
Premier réflexe : utiliser des outils de visualisation.
Et ironiquement, on peut s'aider de... l'IA aussi pour ça.
Des solutions open source permettent d'analyser et proposer des visuels de votre code.
Par exemple :
DeepWiki-open peut vous aider à mapper votre codebase.
gitdiagram peut vous aider à visualiser la structure de votre codebase.
Pour toute autre librarie public, vous pouvez modifier github.com par gitdiagram.com ou deepwiki.com dans l'url.
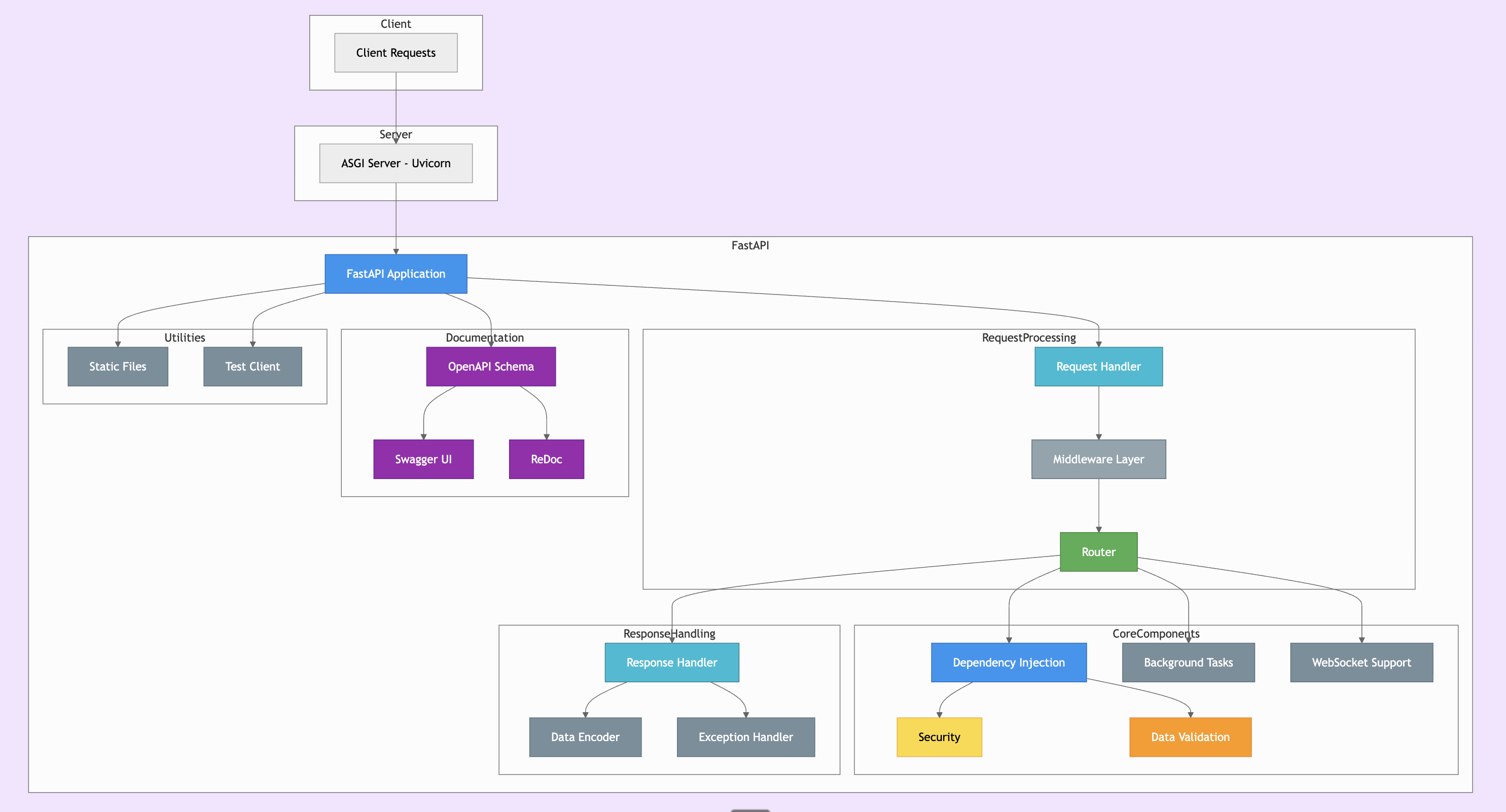
Ces outils sont une première couche utile pour garder une vue d'ensemble.
Mais attention : le fond du problème reste identique.
Ce n'est pas parce qu'on a un joli diagramme qu'il faut déconnecter son cerveau et laisser l'IA générer à foison. La carte n'est pas le territoire. Et un schéma de code n'est pas la compréhension du code.
2. Segmenter par features aussi petites et indépendantes que possible
Ne générez pas 2000 lignes de code d'un coup.
Découpez votre travail en features :
Chaque feature = une itération de compréhension.
Plus les itérations sont courtes, moins l'écart entre votre mental model et la réalité peut se creuser.
Mais voilà les techniques qui changent vraiment la donne :
a) Définir soigneusement l'architecture en amont de la feature
Avant de laisser l'IA coder, posez-vous :
L'architecture, c'est votre job. Pas celui de l'IA. L'IA peut suggérer, mais c'est vous qui décidez.
b) Définir des contrats avec l'IA via des tests
Et voilà LE game-changer : définir des contrats clairs avec l'IA via des tests unitaires et d'intégration.
Avant chaque feature, définissez précisément les résultats attendus.
Pas en prose vague. En tests concrets.
Oui, au final, la technique la plus redoutable est simplement... du TDD.
Ces notions ultra connues et prédominantes dans le software engineering.
Mais appliquées au vibe coding, elles deviennent encore plus puissantes.
Le processus TDD + IA
Avant :
"IA, je veux une feature X qui fait Y"
→ L'IA génère 500 lignes
→ Vous croisez les doigts
→ Ça marche... ou pas
→ Vous ne savez pas vraiment ce qui se passe
Avec TDD + IA:
"Je veux X. Commençons par brainstormer les tests."
1. Il faut qu'on valide ce cas
2. Plus ce cas edge
3. Plus ce cas d'erreur
4. Plus cette intégrationetc...
→ L'IA génère les tests unitaires/intégration
→ **Review sérieuse de votre part**
→ L'IA génère ensuite le code en essayant de valider les tests
→ **Règle principale : ne pas toucher aux tests**
(ou alors avec human-in-the-loop + justification)
Pourquoi ça change tout ?
Les tests deviennent votre ancre de compréhension.
Chaque test unitaire doit être soigneusement créé par vous. Au moins dans la partie use-cases principaux.
Bien sûr, l'IA peut vous aider à :
Mais la validation des tests, c'est vous.
Le contrat est simple :
Si l'IA veut modifier un test, alerte rouge.
Soit elle n'a pas compris le besoin, soit votre test n'était pas clair. Dans tous les cas : human-in-the-loop obligatoire + justification.
Une fois tous les tests passés, ce n'est pas fini.
Review rapide :
Refactoring si nécessaire :
Si vous voyez du code douteux, refactorez.
Les tests sont là pour vous protéger.
Astuce : vous pouvez même demander à l'IA de se review elle-même en première couche :
"Review ce code, détecte les risques et propose des refactorings"
Mais encore une fois : c'est vous qui validez.
Le cercle vertueux
Avec cette approche :
Voilà comment augmenter la qualité du code vibecoder infiniment.
Oui, vibecoder aveuglément est une stratégie de tête brûlée.
Mais vibecoder avec une stratégie prédéfinie... c'est fatal.
Article par B.ERRAJI, consultant data OSSIA - SONATE


La GenAI ne remplace pas le data engineering, elle le redéfinit — et rend votre rôle plus stratégique que jamais.

Découvrez en plus sur CQRS à travers des bonnes pratiques et des points de vigilance !







