
.png)
Nous suivre


On parle beaucoup d'agents en ce moment. Sincèrement, n'importe qui peut en créer un en trois clics aujourd'hui. Le vrai sujet n'est pas là.
La vraie question : à quel point cet agent est efficace ? Et surtout : à quel point évolue-t-il dans son environnement ?
Si je m'intéresse autant à ce sujet, c'est en partie pour contrer un vieux traumatisme data : le drift, quand la distribution des données change et que ton modèle commence à raconter n'importe quoi. Quiconque a déployé un modèle en prod connaît cette angoisse.
Du coup, je me suis penché sur les techniques qui existent pour se rapprocher d'un agent capable de s'auto-améliorer. Mais d'abord, de quoi parle-t-on exactement ?
Un agent "self-improving" répond à trois critères :
1. Il modifie son comportement au fil du temps
2. Le changement vient de sa propre expérience, pas uniquement d'annotations humaines
3. Le mécanisme est intégré dans sa boucle d'exécution, pas un fine-tuning ponctuel tous les six mois
Mon point de vue : je reste convaincu que le self-improvement ne marchera vraiment que si une partie des feedbacks est monitorée par l'humain.
Pourquoi ? Le risque majeur, c'est le biais auto-renforcé. Un agent laissé seul peut s'enfermer dans des minima locaux et optimiser... dans la mauvaise direction. L'humain, même en surface, évite que l'agent se bloque et débloque des niveaux d'efficacité record.
Le 100% self-made agent n'est pas pour demain.
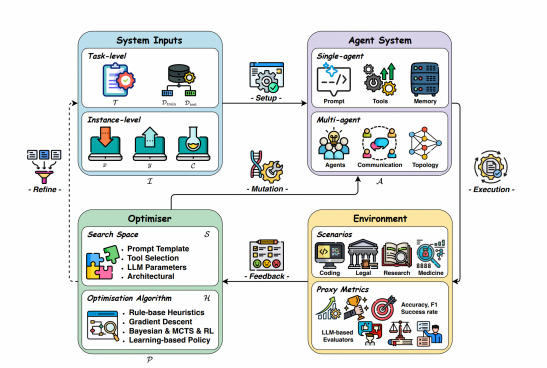
L'agent évolue dans un environnement, reçoit du feedback, et un optimiseur vient raffiner ses composants (prompts, outils, paramètres, architecture). Notez que le "Refine" en entrée suppose une curation des données, c'est là que l'humain intervient.
La forme la plus simple. Reflexion:
Léger, rapide, compatible avec n'importe quel LLM. Mais les améliorations sont éphémères, c'est une optimisation runtime, pas de l'apprentissage long-terme.
C'est un excellent point de départ, mais ce n'est pas de l'apprentissage long-terme, plutôt une optimisation runtime.
Exit le Prompt Engineering Manuel. C'est l'une des tâches les plus ennuyantes que je fuis au maximum. Mais on peut l'automatiser avec DSPy. et ça nous permet d'avoir une étape intermédiaire dans la boucle d'auto-amélioration avant de toucher aux poids.
L'idée :
Limites
Le levier le plus puissant à long terme.
1. Récolter la data de prod: les vraies interactions
2. Annoter: d'abord par des humains
3. Réentraîner sur ces traces
Ça peut commencer simplement : un joli dataset d'évaluation qu'on enrichit petit à petit. Des humains annotent, on accumule. Et progressivement, on fait en sorte que l'agent lui-même note et évalue ses traces, en se basant sur les feedbacks humains précédents.
C'est là que les traces (ou trajectoires) deviennent centrales : une trace, c'est l'historique complet d'une interaction — les actions de l'agent, les réponses de l'environnement, le résultat final. C'est de l'or pour l'apprentissage.
Progressivement, l'agent peut lui-même noter ses traces en se basant sur les feedbacks humains précédents.
Chaque succès est stocké, puis réutilisé comme exemple in-context pour les futures tâches.
Chaque fois que l'agent résout une tâche avec succès, il stocke la trajectoire complète. Pour les tâches futures, il s'envoie quelques trajectoires réussies passées comme exemples in-context.
C'est de l'experience replay pour le prompting.
Limites
Pour le multi-agent, j'ai trouvé une solution très intéressante dans l'article de Self-Improving Multi-Agent Systems :
Limites
Testés et approuvés :
Conclusion
Un agent qui s'auto-améliore, réaliste ? Oui. Les techniques existent et fonctionnent.
Mais pas en autonomie totale. L'humain reste dans la boucle pour éviter les dérives.
Ma recette sans forcément de fine-tuning poussé:
1. Réflexion en temps réel — gains rapides
2. Optimisation de prompts (DSPy)
3. Boucle data vertueuse — récolter, annoter, réentraîner
4. Traces comme mémoire — experience replay
5. Humain dans la boucle — toujours
Le self-improvement n'est plus de la science-fiction. C'est un ensemble de patterns d'ingénierie qu'on peut assembler dès aujourd'hui. La question n'est plus "est-ce possible ?" mais "comment le faire de manière robuste et contrôlée ?".
Et ça, c'est un problème d'ingénierie. Mon domaine préféré.
Article par B.ERRAJI, consultant data OSSIA - SONATE
.png)
Notre article explique comment tirer parti du Vibe Coding tout en gardant contrôle, visibilité et qualité.









