

Nous suivre



Les modèles de langage (LLMs) ont atteint un plateau technique impressionnant. GPT-4, Claude, Gemini…
Leurs capacités convergent vers une asymptote de performance.
La course au nombre de paramètres n’impressionne plus – surtout que cela implique « plus coûteux ».
On veut petit & performant.
Et pour ça, le nouveau terrain de jeu ? Le contexte.
La vraie bataille se joue sur ce qu’on envoie au modèle, pas sur le modèle lui-même.
On appelle ça le context engineering : l’art de fournir au LLM exactement ce dont il a besoin, au bon moment, dans le bon format.
La solution est donc d’améliorer le système autour du modèle et d’envoyer le contexte le plus pertinent pour une tâche donnée, afin de ne retenir que les éléments essentiels à la réponse.
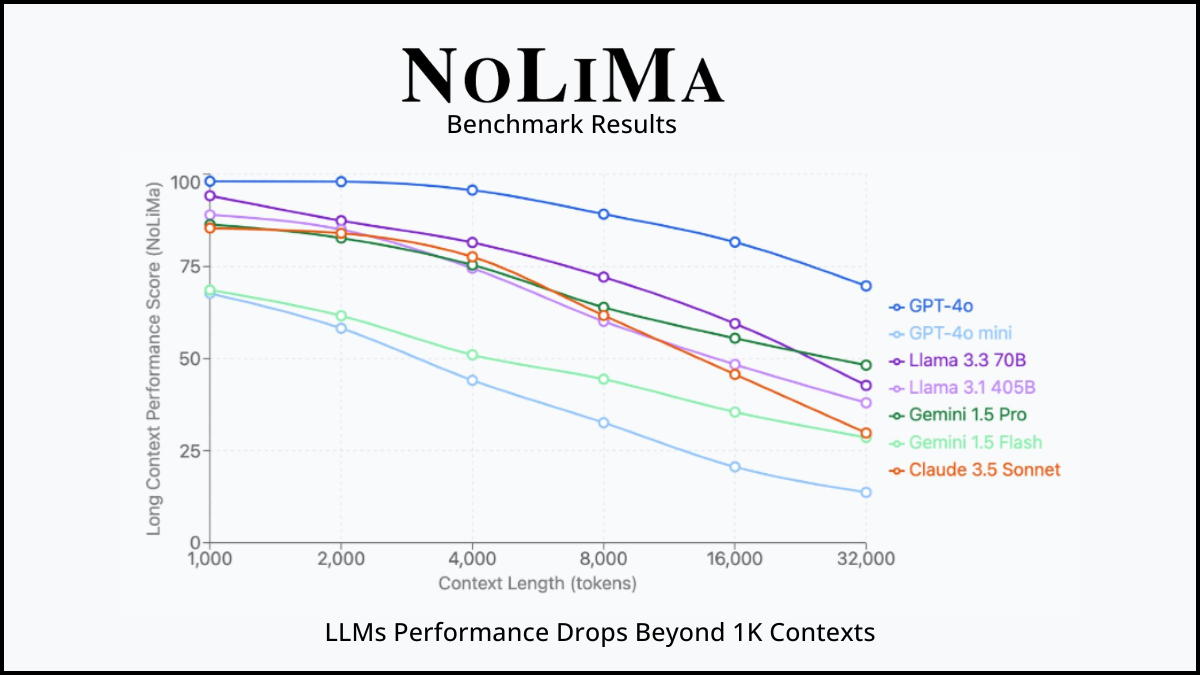
Il ne faut pas noyer un LLM sous la donnée, ni provoquer des hallucinations (cf. études montrant que plus le contexte grandit, plus les performances des LLM chutent drastiquement – au-delà de 30k/40k tokens, on observe cette chute dans énormément de modèles, surtout open source).
NoLiMa : Long-Context Evaluation Beyond Literal Matching
Et l’un des outils les plus puissants pour le context engineering est le Knowledge Graph.
Les graphes capturent la structure et les relations du monde réel.
Imaginez : au lieu de chercher « dans quels documents parle-t-on de X ? », vous pouvez demander
« quelles sont les entités connectées à X, et comment ? » ou « quel chemin relie X à Y ? ».
C’est ce mariage entre graphes de connaissances et semantic embedding que nous allons explorer : le GraphRAG.
Avant de plonger dans le GraphRAG, alignons-nous sur deux concepts fondamentaux.
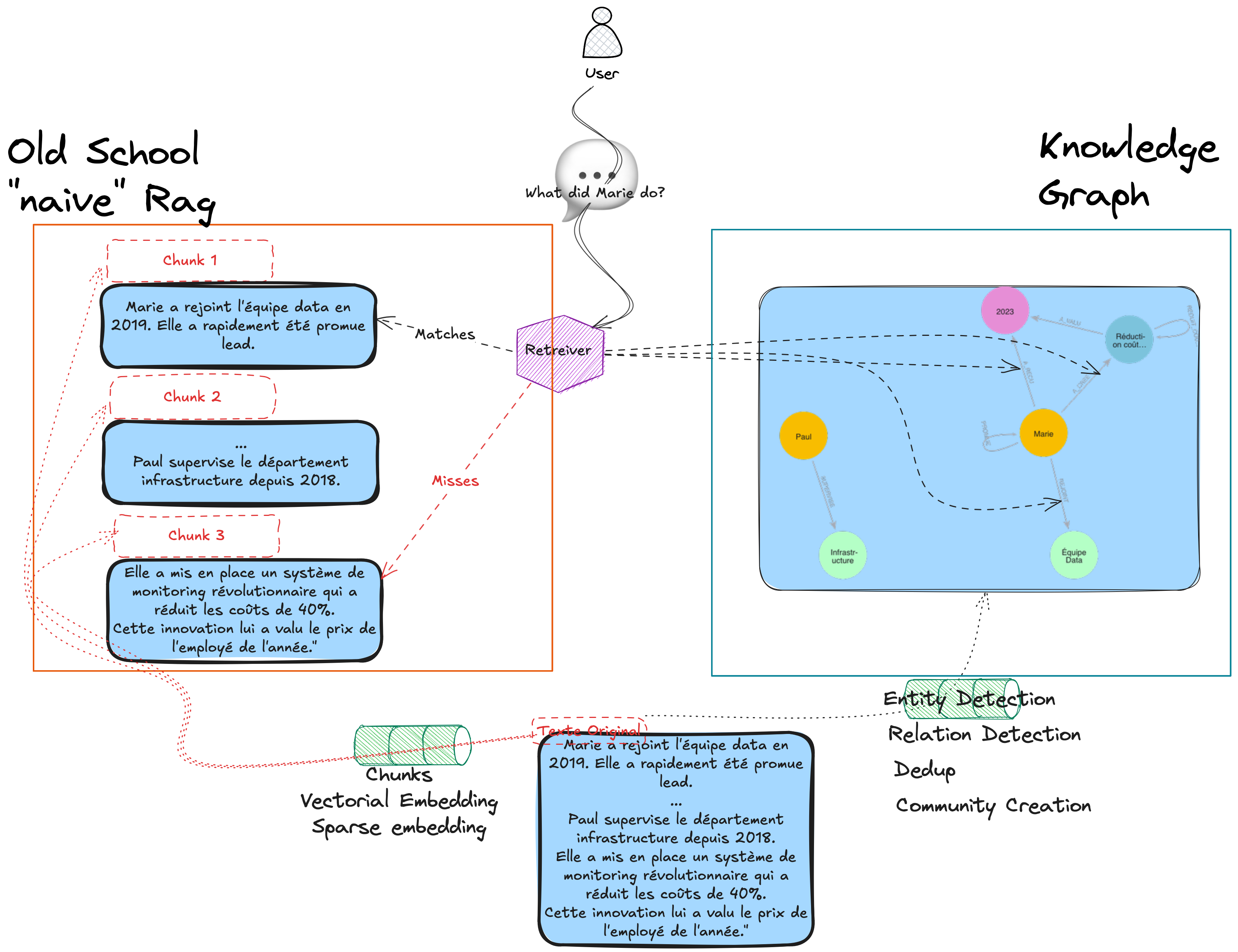
Souvent, quand on parle de RAG, les gens pensent instantanément (et injustement) à embedding + VectorDB, parce que c’est la technique la plus accessible.
Appelons-la plutôt Naive RAG.
Et redéfinissons correctement le terme RAG :
Le RAG améliore les réponses d’un LLM en trois étapes :
Exemple concret :
Question : « Quel est le chiffre d’affaires de notre Q3 ? »
→ Retrieve : « Récupère le rapport financier Q3 » (quelle que soit la technique de retrieval – naïve, hybride, etc.)
→ Augment : « Voici les documents associés… [contexte] »
→ Generate : « Le CA du Q3 est de 2,4 M€, en hausse de 15 %. »
Le Naive RAG classique utilise principalement la similarité vectorielle : on transforme textes et questions en embeddings, puis on cherche les plus proches voisins.
Simple, efficace, mais… limité.
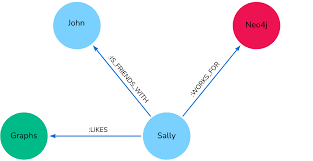
Un graphe est une structure de données composée de :
Pourquoi c’est puissant ?
Parce que les graphes capturent comment les choses sont connectées, pas seulement ce qu’elles sont.
Exemple simple :
[Alice] --travaille_pour--> [Anthropic]
[Alice] --connaît--> [Bob]
[Bob] --travaille_pour--> [OpenAI]
Avec cette structure, on peut répondre à des questions comme « Qui connaît quelqu’un chez OpenAI ? » en traversant le graphe.
Impossible avec une simple recherche vectorielle !
Le mariage : GraphRAG
GraphRAG = Structure relationnelle + Retrieval intelligent
Au lieu de chercher des chunks de texte similaires, on :
La différence ?
Le RAG classique trouve des documents proches sémantiquement.
Le GraphRAG trouve des informations reliées logiquement, même si elles sont dispersées dans différents documents.
Soyons honnêtes : pour des questions directes et factuelles, tous les RAG se valent à peu près.
Exemple :
Question : « Qu’est-ce que StateGraph dans LangGraph ? »
✅ Naive RAG : trouve le chunk qui définit StateGraph
✅ Hybrid RAG : idem, avec un meilleur ranking
✅ GraphRAG : idem aussi
Verdict : pour une recherche « 1-hop » (une seule étape de raisonnement), pas besoin de sortir l’artillerie lourde.
Les choses deviennent intéressantes quand la réponse nécessite de connecter plusieurs informations dispersées.
Exemple 1 – Documentation technique :
Question : « Quels composants de LangGraph utilisent à la fois Channel et supportent la persistance via Checkpointer ? »
[StateGraph] --utilise--> [Channel]
[StateGraph] --supporte--> [Checkpointer]
[CompiledGraph] --utilise--> [Channel]
[CompiledGraph] --supporte--> [Checkpointer]
→ Traverse le graphe : intersection des nœuds qui ont BOTH relations
→ ✅ Réponse précise : StateGraph, CompiledGraph
Exemple 2 – Connaissance factuelle :
Question : « Que fait aujourd’hui le fils aîné du capitaine de l’équipe de France championne du monde 1998 ? »
Raisonnement nécessaire :
Avec Naive RAG : peu de chances que tout soit dans les k-nearest chunks → hallucinations possibles.
Avec GraphRAG : on traverse explicitement les relations ; le contexte récupéré contient toute la chaîne logique.
.png)
Construire un GraphRAG se fait en deux temps : construire le graphe, puis l’interroger. Voyons comment transformervos documents en réseau de connaissances.
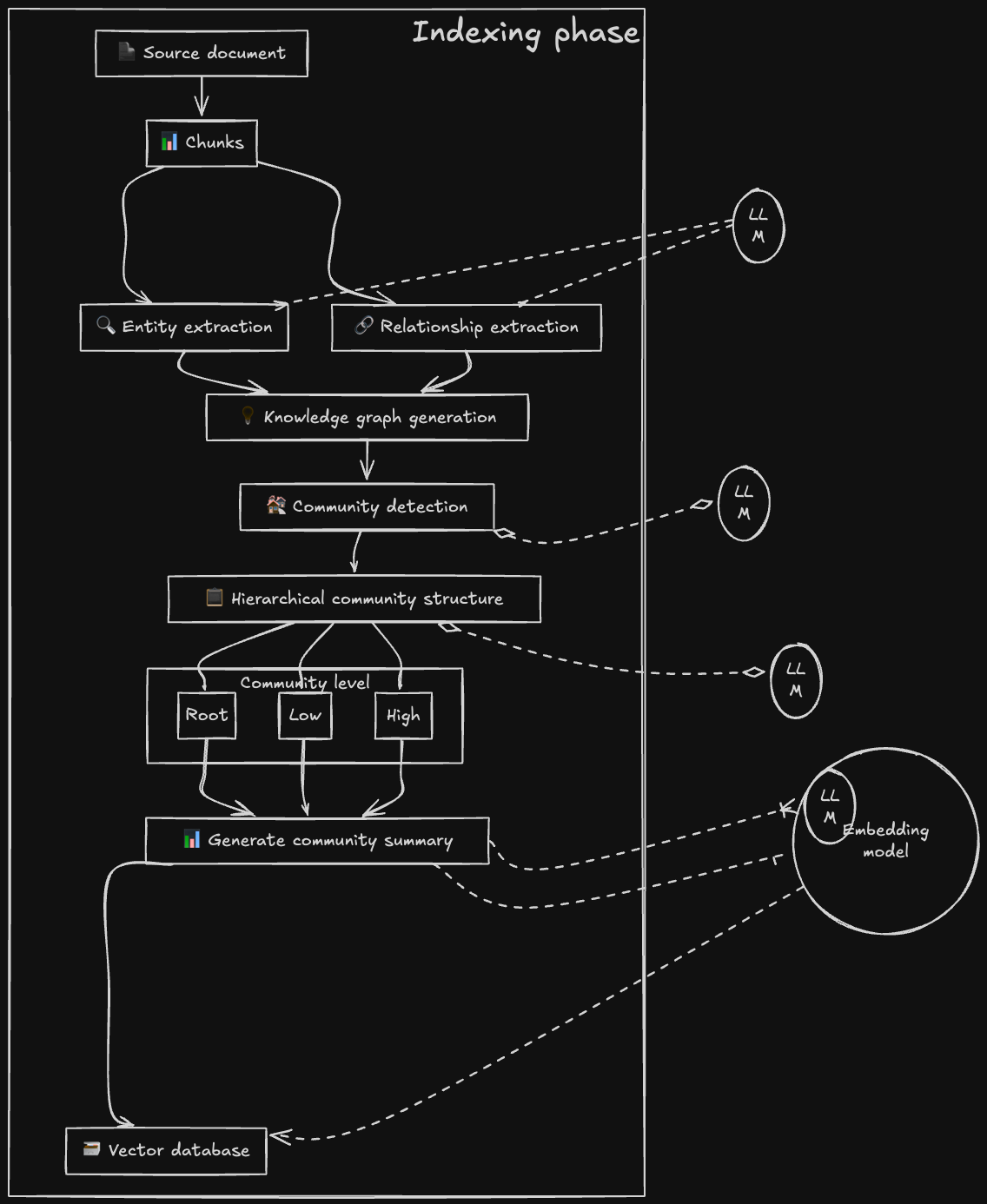
Comme pour le RAG naïf, on découpe les documents en morceaux (300-1200 tokens), en respectant les frontières logiques pour ne pas casser les relations.
Document → Chunks + overlap 10-20%
Alignés sur les documents (1 doc = N chunks)
Un LLM (ou un modèle NLP spécialisé) extrait les triplets : (Entité 1, Relation, Entité 2)
Texte: "StateGraph extends Graph and uses Channel for state management"
Extraction:Types courants en doc technique :
→ (StateGraph, EXTENDS, Graph)
→ (StateGraph, USES, Channel)
→ (Channel, MANAGES, State)
> Entités : Class , Method , Concept , PatternRelations :
> EXTENDS , USES , DEPENDS_ON , IMPLEMENTS
Les triplets identiques sont fusionnés (même source, même cible = même relation). Les descriptions multiples sont combinées
// Dans Neo4j
CREATE (sg:Class {name: "StateGraph"})-[:EXTENDS]->(g:Class {name: "Graph"})
CREATE (sg)-[:USES]->(c:Class {name: "Channel"})
Point clé : On garde les chunks originaux liés aux entités via FROM_CHUNK pour la traçabilité.
Microsoft pousse le concept plus loin avec une hiérarchie de communautés :
L’algorithme regroupe les entités fortement connectées en communautés hiérarchiques.
Niveau 0 : Graphe complet
Niveau 1 : Grandes communautés thématiques
Niveau 2 : Sous-communautés spécialisées
...
Exemple :
Communauté "State Management":
StateGraph, Channel, Checkpointer, MemorySaver
Communauté "Execution Engine":
CompiledGraph, Pregel, Executor
Chaque communauté obtient un résumé généré par LLM contenant :
Pourquoi c’est puissant ?
Questions globales : interroger les résumés de haut niveau (“Vue d’ensemble de LangGraph”)
Questions locales : plonger dans une sous-communauté (“Comment fonctionne le checkpointing ?”)
On ajoute des vecteurs aux nœuds pour combiner :
Input :
"StateGraph extends Graph. It uses Channel for state management and works with Checkpointer to persist state across executions."
Output graphe :
[StateGraph] --EXTENDS--> [Graph]
[StateGraph] --USES--> [Channel]
[StateGraph] --WORKS_WITH--> [Checkpointer]
[Checkpointer] --ENABLES--> [Persistence]
+ Communauté détectée :
Community "State Management" (Level 1): Requête possible :
Entities: StateGraph, Channel, Checkpointer
Report: "Composants gérant la persistance d'état..."
"Quels composants utilisent Channel ET gèrent la persistance ?"
→ Traverse le graphe : trouve StateGraph ✅

Règle d’or :
Commencez simple, puis enrichissez selon les besoins.
Un graphe basique bien fait > un graphe complexe mal construit.
Une fois le graphe construit, tout se joue sur la manière de l’interroger.
Trois approches principales :
Pour quoi ?
→ Questions ciblées sur des entités précises.
Comment ça marche ?
Exemple :
“Comment StateGraph gère-t-il les checkpoints ?”
→ Trouve StateGraph
→ Explore ses relations
→ Récupère Checkpointer, MemorySaver, et les chunks associés
Flow simplifié :
Question
→ Entités de départ (vector search)
→ Voisinage (graph traversal)
→ Contexte enrichi → Réponse
Pour quoi ?
→ Questions générales nécessitant une compréhension globale.
Comment ça marche ?
Exemple :
“Quelles sont les principales capacités de LangGraph ?”
→ Analyse de tous les rapports thématiques
→ Synthèse globale cohérente
⚠️ Trade-off : plus complet, mais plus coûteux (tokens et temps).
Innovation récente : une recherche locale enrichie des insights communautaires.
Principe :
Exemple :
“Comment implémenter un workflow avec retry logic et human-in-the-loop ?”
DRIFT décompose :
✅ Résultat : réponses plus riches sans exploser les coûts comme le Global Search.
.png)
❌ Coût initial : la construction du graphe nécessite du temps et des appels LLM.
Qualité de l’extraction : les LLM peuvent halluciner lors de l’extraction des triplets — comment valider ?
Fusion d’entités : “Alice”, “Alice Smith”, “A. Smith” → problème de résolution d’entités non trivial.
Conception du schéma : relations trop génériques = bruit ; trop spécifiques = maintenance lourde.
❌ Complexité technique : nécessite une bonne maîtrise des bases de données orientées graphe.
Graph drift : comment maintenir la cohérence lors de l’ajout de nouveaux documents ?
❌ Maintenance : la mise à jour du graphe n’est jamais triviale.
Le Knowledge Graph n’est pas simplement une amélioration du RAG classique :
c’est un changement de paradigme.
Là où le RAG vectoriel cherche des documents similaires, le GraphRAG navigue dans un modèle structuré du domaine.
Cette différence est fondamentale :
En représentant explicitement les entités et leurs relations, on ne stocke plus de l’information, on capture la connaissance.
Une fois votre domaine modélisé en graphe, tout l’arsenal de la data science des graphes devient accessible :
Le graphe devient une plateforme : un investissement initial unique, pour une infinité d’applications.
Sources :
https://neo4j.com/blog/genai/what-is graphrag/
https://microsoft.github.io/graphrag/index/overview/
https://microsoft.github.io/graphrag/query/overview/
Article par B.ERRAJI, consultant data OSSIA - SONATE


Découvrez une analyse de l'impact des LLMs sur la productivité, avec des conseils pratiques pour optimiser leur utilisation et éviter les pièges courants.

Chaque fin de mois retrouvez une sélection de l'info du monde de l'IT et de la tech !







