

Le System Design, ce n’est pas viser la perfection : c’est apprendre à choisir les bons compromis.
Nous suivre


Imaginez : votre application compte 10 000 utilisateurs actifs. Vous voulez qu'elle reste disponible 100% du temps, que chaque requête soit traitée instantanément, que les données soient toujours parfaitement synchronisées, c'est à dire que les utilisateurs voient la dernière version de la donnée disponible.
Spoiler alert : C'est conceptuellement impossible.
Bienvenue dans le monde du System Design, où l'art consiste non pas à atteindre la perfection, mais à choisir intelligemment les bons compromis selon les prérequis.
Et ne vous y trompez pas, que vous soyez dev, dev web, dans la data, architecte, cloud engineer, vous aurez besoin de comprendre et de maîtriser le system design à un moment donné de votre carrière. Le plus tôt le mieux..
Dans cet article, nous allons démystifier les concepts importants et avoir une vision globale des différents éléments composant un système scalable, résilient, et performant. Histoire d'en prendre conscience et de savoir comment guider nos choix futurs. Et je vous invite fortement à creuser chacun de ces concepts primordiaux.

En 2000, Eric Brewer a énoncé une conjecture qui allait devenir l'un des principes fondamentaux du system design : le théorème CAP. Ce théorème stipule qu'un système distribué ne peut garantir simultanément que deux des trois propriétés suivantes :
> Consistency (Cohérence) : Tous les nœuds voient exactement la même donnée au même moment
> Availability (Disponibilité) : Le système reste opérationnel et répond toujours aux requêtes
> Partition Tolerance (Tolérance aux partitions) : Le système continue de fonctionner même si des messages sont perdus entre les nœuds
Imaginez deux serveurs qui doivent maintenir le solde d'un compte bancaire. Si le réseau entre eux est coupé (partition réseau) :
> Si vous choisissez Cohérence + Tolérance aux partitions (CP) : Vous refusez les transactions jusqu'à ce que les serveurs puissent se synchroniser. Votre système n'est plus disponible.
> Si vous choisissez Disponibilité + Tolérance aux partitions (AP) : Vous acceptez les transactions sur chaque serveur indépendamment. Les soldes peuvent diverger temporairement.
> Si vous choisissez Cohérence + Disponibilité (CA) : Vous supposez que le réseau ne tombera jamais en panne. Spoiler : le réseau tombera en panne.
Dans le monde "moderne", on le verra un peu plus tard dans l'article, le choix n'est pas binaire -> Cohérent ou pas cohérent mais plutôt plutôt un spectre de possibilités.
La scalabilité est probablement le défi le plus visible du system design. Votre startup, votre application ou que sais-je a du succès, les utilisateurs affluent, et soudain votre serveur unique commence à suffoquer. Que faire ? C'est là que se pose la question fondamentale : monter ou multiplier ?
Scale Up (Vertical) vs Scale Out (Horizontal)
Le scale up (ou scaling vertical), c'est l'approche "force brute".
Imaginez-le comme passer d'une Twingo à une Ferrari : c'est toujours une seule voiture, mais avec infiniment plus de puissance sous le capot. Concrètement, vous augmentez CPU, RAM et stockage sur la même machine.
✅ Simple : pas de changement de code
✅ Cohérence garantie : une seule machine
❌ Limite physique : on ne peut pas ajouter infiniment de RAM
❌ Coût exponentiel : passer de 64 à 128 GB de RAM peut doubler le prix
Le scale out (scaling horizontal), c'est l'approche "armée de clones". Au lieu d'une supercar, vous gérez une flotte Uber : plus de demande = plus de voitures. Vous ajoutez des serveurs identiques qui se partagent la charge.
✅ Scalabilité infinie : ajoutez autant de serveurs que nécessaire
✅ Coût linéaire : 10 serveurs à 1000€ vs 1 serveur à 10000€
❌ Complexité : gérer la synchronisation, les données distribuées
❌ Overhead réseau : communication entre serveurs
Règle pratique : Commencer vertical jusqu'à ~100K utilisateurs, puis passer horizontal. une seule instance 128Gb de RAM peut gérer ÉNORMEMENT de charge. (Je vous renvoie vers ma série d'articles sur comment je gérais 4M de requête quotidienne sur un VPS de 4gb de RAM )
Passons maintenant à un aspect souvent mal compris : la disponibilité. Dans l'industrie, on parle des "fameux 9" - mais que signifient-ils vraiment ?

Chaque "9" supplémentaire multiplie exponentiellement les coûts et la complexité. Passer de 99,9% à 99,99% nécessite souvent : redondance multi-région, failover automatique, chaos engineering, équipe SRE dédiée, monitoring avancé, et des tests de disaster recovery mensuels.
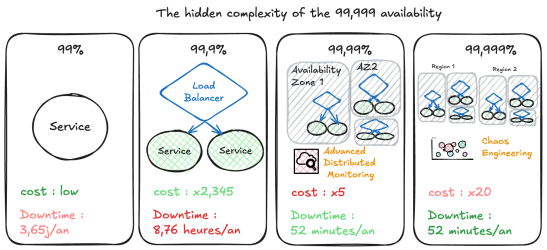
Pas besoin de chercher le 99,999 si vous n'en avez pas besoin. Pour les systèmes critiques comme le système bancaire, Ce choix se justifie car le coût du downtime est très élevé. Par contre pour un service interne, un blog, un portfolio, un site vitrine, 99% c'est tout à fait acceptable.
La performance n'est pas un nombre unique - c'est un équilibre délicat entre deux forces parfois opposées. Latence : La perception de vitesse
La latence, c'est le temps pour traiter UNE requête individuelle. C'est ce que ressent directement l'utilisateur :
> API REST : < 100ms (perception instantanée)
> Page web : < 3 secondes (40% d'abandon au-delà)
> Base de données : < 10ms pour une lecture simple
Throughput : La capacité brute
Le throughput, c'est combien de requêtes vous pouvez traiter par seconde au total :
> API moderne : 1000-10000 req/s par serveur
> Base de données : 10000-100000 queries/s (selon complexité)
Le piège :
Tester en prod sur un serveur vide est trompeur. Il faut faire du load testing pour vraiment comprendre les performances de son système.
Quand vous et votre collègue êtes les seuls utilisateurs, vous ne verrez pas les problèmes.
Et pour rajouter un peu de challenge et rester dans l'optique des "compromis", optimiser l'un peut dégrader l'autre. Le batching améliore le throughput mais augmente la latence.
On en avait parlé plutôt dans la partie I de l'article, on va revenir dessus ici rapidement.
Strong Consistency : La vérité absolue
Tout le monde voit exactement la même chose, instantanément, comme s'il n'y avait qu'une seule copie de la donnée.
Exemple : Solde bancaire après virement
Coût : Latence élevée, disponibilité réduite
Eventual Consistency : La promesse du futur
Les données finiront par converger... mais on ne sait pas exactement quand.
Exemple : Nombre de likes sur Instagram
Avantage : Performance et disponibilité maximales
Bounded Staleness : Le compromis intelligent
Les données peuvent être obsolètes, mais dans une fenêtre de temps garantie.
Exemple : Stock produit mis à jour toutes les 5 secondes
Compromis : Balance entre performance et fraîcheur
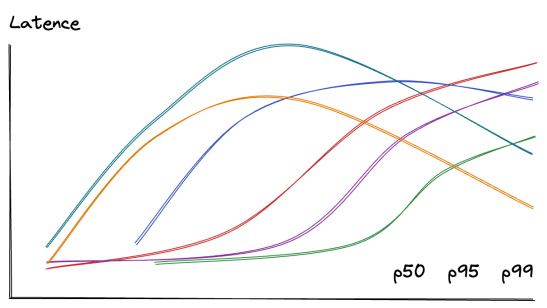
Un dernier point crucial avant de passer aux patterns architecturaux : mesurez ce qui compte, pas ce qui est facile à mesurer.
P50 (médiane) : 50% des requêtes sont plus rapides
P95 : 95% des requêtes sont plus rapides
P99 : Les 1% les plus lentes (vos utilisateurs les plus frustrés)
Exemple réel :
P50 = 50ms → La plupart des users sont contents
P95 = 200ms → Acceptable
P99 = 3s → 1% d'users très mécontents = problème à régler
Règle d'or : Ne regardez jamais que la moyenne. Une moyenne de 100ms peut cacher des requêtes à 10 secondes qui font fuir vos clients.
Un monolithe est une application construite comme une unité unique et indivisible. Tout le code - interface utilisateur, logique métier, accès aux données - est regroupé dans une seule base de code, déployée comme un seul bloc.
Caractéristiques du monolithe :
> Une seule base de code --> un seul repo, un seul déploiement
> Un processus unique en exécution -> stack trace complète, logs centralisés
> Une base de données partagée -> coût réduit, gestion simplifiée, cohérence garantie
> Déploiement "tout ou rien"
Mais on peut en arriver à certaines limites :
> Scalabilité limitée (tout scale ensemble) : RAM max, CPU max, stockage max sur une seule machine éventuellement atteint.
> Un bug peut faire tomber toute l'application : Si mal géré, cela peut être dramatique.
Exemples de succès : Shopify (1M+ req/min), GitHub, Stack Overflow - tous utilisent des monolithes avec succès.
Les microservices décomposent l'application en plusieurs services indépendants, chacun responsable d'une fonctionnalité métier spécifique. Chaque service :
Possède sa propre base de données
Est déployé indépendamment -> Scalabilité ciblée (scale uniquement ce qui en a besoin)
Cela implique naturellement une isolation des pannes
On peut adapter la stack technique au service.
Communique via API (REST, gRPC) ou messages
Structure microservices :
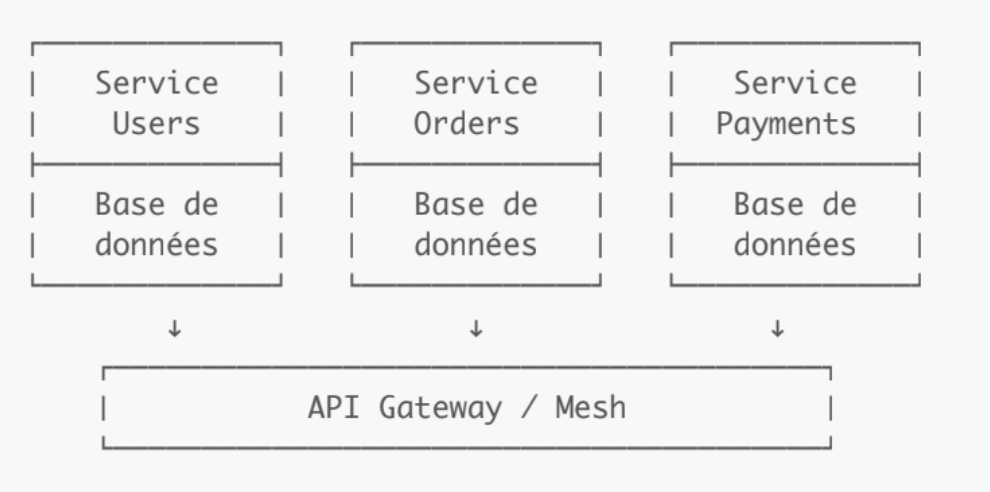
Mais on peut en arriver à une complexité cachée non triviale :
> Complexité réseau : Latence inter-services (~1ms vs ~0.001ms en monolithe)
> Transactions distribuées : Pas de rollback simple
> Debugging complexe : Distributed tracing nécessaire
> Overhead opérationnel : 10 services = 10x CI/CD, monitoring, logs
Face aux extrêmes, une approche intermédiaire émerge : le monolithe modulaire. C'est l'architecture que Shopify, Spotify et bien d'autres ont adopté avant d'éventuellement migrer vers les microservices.
/app
/users # Module indépendant
/api
/domain
/repository
/orders # Communication via interfaces
/api
/domain
/repository
/shared # Code partagé minimal
Règle de Conway : Votre architecture reflètera votre organisation.
> 3 équipes = 3 services maximum au début
> 10 développeurs = restez monolithe
L'architecture orientée événements représente un changement de paradigme : au lieu d'appels synchrones directs, les services communiquent via des événements asynchrones.
Pub/Sub Pattern :
Service Orders publie : "OrderCreated"
→ Service Email s'abonne et envoie confirmation
→ Service Inventory s'abonne et réduit stock
→ Service Analytics s'abonne et track metrics
Découplage temporel : Le publisher n'attend pas les consumers
Scalabilité naturelle : Ajoutez des consumers selon la charge
Résilience built-in : Un consumer down n'affecte pas les autres
Évolutivité : Ajoutez de nouveaux consumers sans toucher aux existant
Technologies 2025 :

Test décisif : Si vous ne pouvez pas dessiner votre architecture sur un tableau blanc en 5 minutes, elle est trop complexe.
Les load balancers distribuent le trafic entrant entre plusieurs serveurs pour optimiser l'utilisation des ressources et assurer la haute disponibilité.
C'est un composant intelligent qui prend des décisions complexes en millisecondes. Il maintient l'état de santé de chaque serveur, route intelligemment les requêtes, et peut même optimiser pour la localité des données.
Types d'algorithmes :
> Round Robin : Distribution cyclique simple
> Least Connections : Vers le serveur le moins chargé
> ...
Technologies populaires :
> Nginx : HTTP/HTTPS, reverse proxy
> Traefik : Cloud-native, auto-discovery
> Cloud exemple : AWS ALB/NLB : Managed, auto-scaling
C'est un DES choix les plus IMPORTANTS que vous aurez à faire. Car les éléments stateful sont souvent les plus gros bottlenecks en général!
Explorons les nuances au-delà du simple "SQL vs NoSQL".
SQL vs NoSQL : La matrice de décision
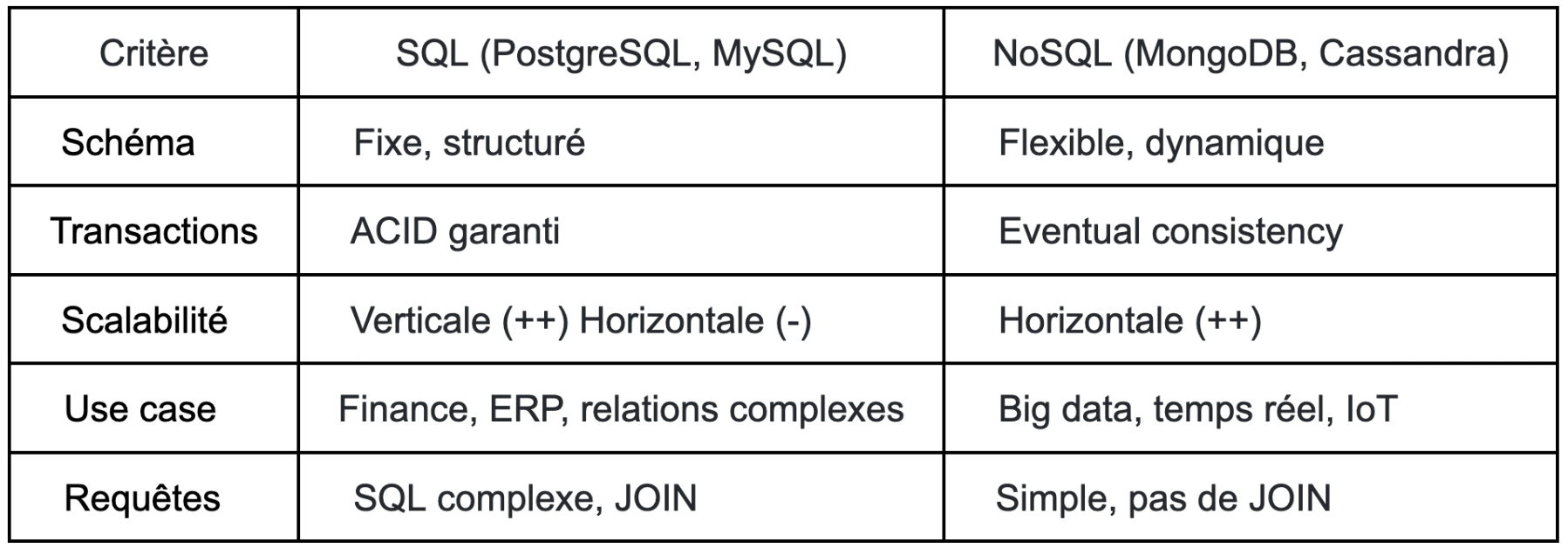
Les bases relationnelles restent le choix par défaut pour une excellente raison : elles offrent des garanties ACID complètes, un langage de requête puissant (SQL), et des décennies d'optimisation.
Alors que
NoSQL n'est pas UNE technologie mais une famille de solutions spécialisées, chacune optimisée pour des patterns spécifiques.
Quand une seule instance de base de données ne suffit plus, il faut distribuer. Mais attention, c'est là que la complexité explose.
Sharding : Distribution horizontale des données sur plusieurs serveurs
-- Exemple : Sharding par user_id
-- Serveur 1 : users 1-1000000
-- Serveur 2 : users 1000001-2000000
-- Serveur 3 : users 2000001-3000000
-- Hash-based sharding
shard_id = hash(user_id) % nb_shards
Généralement est faite sur des dates, des groupes d'IDs, des régions, etc.
permet de stocker physiquement les données qui sont requêtées ensemble en générale.
Chaque partition est gérée comme une "sous-table".
> Range-based : Par plage de valeurs (dates, alphabétique)
> Hash-based : Distribution uniforme via fonction de hash
> Geographic : Par région pour réduire latence
> ...
Le cache est souvent présenté comme la solution miracle aux problèmes de performance. La réalité est plus nuancée : mal utilisé, il devient source de bugs subtils et de données inconsistantes.
La hiérarchie du cache :
Browser Cache (0ms)
↓
CDN Edge Cache (10-50ms)
↓
Application Cache - Redis/Memcached (1-5ms)
↓
Database Cache (5-10ms)
↓
Database Disk (10-100ms)
Technologies populaires :
> Redis : Cache + Queue + Pub/Sub
> Memcached : Pure cache
> Caffeine : Java Cache
Un CDN ne sert pas qu'à distribuer des images. C'est devenu une plateforme de calcul distribué à part entière. L'évolution du CDN moderne :
Génération 1 : Cache de fichiers statiques (images, CSS, JS)
Génération 2 : Compression, optimisation, SSL termination
Génération 3 : Edge computing, Workers, personnalisation temps réel
Avantages :
Latence réduite (contenu servi localement)
Charge serveur origine réduite
Protection DDoS
Compression automatique
Providers majeurs :
> Cloudflare : Global, gratuit pour commencer
> AWS CloudFront : Intégration AWS native
> Akamai : Enterprise, plus cher
> Fastly : Real-time purge, edge computing
Les message queues sont le pattern de résilience par excellence. Elles transforment les architectures fragiles synchrones en systèmes robustes asynchrones.
Technologies par use case :

Après avoir exploré les composants individuels, voyons comment les orchestrer pour créer des systèmes véritablement scalables et résilients.
Le partitioning consiste à diviser une grande base de données en segments plus petits et plus gérables. Cette technique améliore drastiquement les performances en réduisant la quantité de données à parcourir pour chaque requête.
Vertical Partitioning : Séparer par colonnes
Imaginez une table utilisateur massive avec 50 colonnes. En pratique, 90% des requêtes n'ont besoin que du nom et de l'email. Le vertical partitioning sépare les colonnes fréquemment utilisées des colonnes "lourdes" (bio, préférences JSON, avatar). Résultat : les requêtes courantes deviennent 10x plus rapides car elles scannent moins de données.
Table Users originale : [id, name, email, bio, avatar, preferences, ...]
↓
Users_Core : [id, name, email] ← Requêtes fréquentes
Users_Profile : [user_id, bio, avatar, preferences] ← Requêtes occasionnelles
Horizontal Partitioning : Séparer par lignes
Au lieu d'avoir une table de 100 millions d'utilisateurs, vous la divisez en segments logiques : users_europe, users_americas, users_asia. Chaque requête ne touche qu'une fraction des données totales. Netflix utilise cette approche par région pour servir efficacement ses 230+ millions d'abonnés.
Replication : Répliquer pour la disponibilité
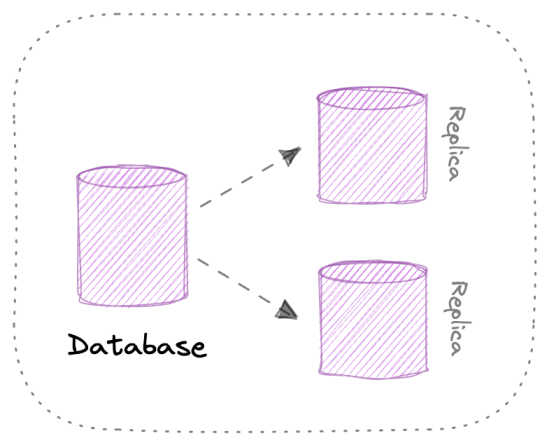
Multi-Master Replication : Écriture multiple
Master 1 : [id, name, email]
slave 1 : [id, name, email]
slave 2 : [id, name, email]
On peut répliquer la donnée sur plusieurs serveurs. Comme ça si le master tombe, les slaves peuvent continuer à servir les requêtes.
Circuit Breaker : Le fusible intelligent
Comme un fusible électrique protège votre maison, le Circuit Breaker protège votre système des services défaillants. Après 5 échecs consécutifs, il "ouvre le circuit" et refuse temporairement les appels vers le service en panne, évitant ainsi l'effet cascade.
État CLOSED (Normal) → Service fonctionne
↓ (5 échecs)
État OPEN (Protection) → Rejette les appels pendant 60s
↓ (Après timeout)
État HALF-OPEN (Test) → Laisse passer 1 requête
↓
Retour à CLOSED si succès, sinon reste OPEN
Netflix utilise massivement ce pattern via Hystrix pour maintenir son service même quand certains microservices tombent.
Retry avec Exponential Backoff : La persévérance intelligente
Au lieu de bombarder un service qui peine, on espace intelligemment les tentatives : 1s, 2s, 4s, 8s, 16s... Cela donne au service le temps de récupérer sans l'écraser davantage. AWS SDK implémente ce pattern par défaut pour toutes ses API.
Bulkhead Pattern : Compartimenter pour survivre
Comme les cloisons étanches d'un navire, le Bulkhead isole les ressources critiques. Si votre service d'analytics consomme toutes les connexions database, les paiements continuent de fonctionner grâce à leur pool de connexions dédié.
Pool Paiements : ████████████ (100 connexions) ! Toujours disponible
Pool Catalogue : ████████ (50 connexions) ! Peut saturer
Pool Analytics : ████ (20 connexions) ! Peut échouer sans impact
Les opérations lourdes (envoi d'email, génération de PDF, calculs complexes) ne doivent jamais bloquer la réponse utilisateur. Le pattern : accepter immédiatement la requête, la mettre en queue, et la traiter en arrière-plan.
Exemple concret : Quand vous uploadez une vidéo sur YouTube, vous recevez immédiatement une confirmation. Le transcodage en différentes qualités (360p, 720p, 1080p, 4K) se fait ensuite de manière asynchrone, parfois pendant des heures.
Un health check est un endpoint simple (/health) qui répond "OK" si tout va bien. Mais les health checks modernes vont plus loin : ils vérifient la base de données, Redis, l'espace disque, et retournent un statut détaillé.
Niveaux de health checks :
> Liveness : Le processus est-il vivant ? (Kubernetes le redémarre sinon)
> Readiness : Peut-il accepte r du trafic ? (Load balancer l'exclut sinon)
> Deep health : Tous les composants sont-ils opérationnels ?
Amazon utilise des "canaries" - des health checks qui simulent de vraies transactions utilisateur toutes les minutes pour détecter les problèmes avant les clients.
L'auto-scaling ajuste automatiquement le nombre de serveurs selon la charge. Quand le CPU dépasse 70%, on ajoute des instances. Quand il descend sous 30%, on en retire.
Métriques de scaling :
> CPU/Memory : Basique mais efficace
> Request rate : 1000 req/s → scale up
> Queue depth : Plus de 100 messages en attente → plus de workers
> Custom metrics : Temps de réponse P95 > 500ms → scale up
Uber scale ses services de matching de 100 à 10,000 instances pendant les heures de pointe du vendredi soir, puis redescend automatiquement.
Authentication vs Authorization : Qui et Quoi
L'authentication répond à "Qui êtes-vous ?" - c'est le processus de vérification d'identité. Les approches modernes utilisent JWT (JSON Web Tokens) pour les API REST, OAuth2 pour la délégation d'accès (login avec Google/Facebook), ou SAML pour l'entreprise.
L'authorization répond à "Que pouvez-vous faire ?" - elle détermine les permissions. RBAC (Role-Based Access Control) assigne des rôles aux utilisateurs (admin, editor, viewer), tandis qu'ABAC (Attribute-Based) offre un contrôle plus fin basé sur des attributs contextuels.
Defense in Depth : Les couches de protection
Comme un château médiéval avec douves, murs et donjon, la sécurité moderne fonctionne en couches :
Internet → WAF (Cloudflare) → Load Balancer → API Gateway (auth)
→ Application (authorization) → Database (encryption)
Chaque couche filtre les menaces : le WAF bloque les attaques communes (SQL injection, XSS), l'API Gateway vérifie les tokens, l'application enforce les permissions, et la base de données chiffre les données sensibles.
L'observabilité moderne repose sur trois piliers complémentaires qui ensemble donnent une vision complète du système :
Metrics : Le tableau de bord temps réel
Les métriques sont des mesures numériques collectées à intervalles réguliers. Prometheus scrape les métriques toutes les 15 secondes, Grafana les visualise en dashboards. Les "Golden Signals" de Google SRE sont essentiels :
> Latency : Temps de réponse (P50, P95, P99)
> Traffic : Requêtes par seconde
> Errors : Taux d'erreur (4xx, 5xx)
> Saturation : Utilisation des ressources
Spotify monitore 10 millions de métriques par seconde pour maintenir son service musical global.
Logs : L'historique détaillé
Les logs structurés (JSON) permettent des requêtes complexes. Au lieu de "User 123 logged in", on log :
{
"event": "user_login",
"user_id": 123,
"ip": "192.168.1.1",
"timestamp": "2025-01-15T10:30:00Z",
"success": true,
"latency_ms": 234
}
L'ELK Stack (Elasticsearch, Logstash, Kibana) est le standard : Logstash collecte, Elasticsearch indexe, Kibana visualise. Netflix génère 4+ pétaoctets de logs par jour.
Distributed Tracing : Suivre une requête
Dans un système microservices, une requête utilisateur peut traverser 10+ services. Le distributed tracing suit cette requête de bout en bout, montrant où le temps est dépensé.
User Request → API Gateway (50ms) → User Service (100ms)
→ Order Service (200ms) → Payment Service (500ms)
→ Notification Service (50ms)
Total : 900ms
Jaeger et Zipkin sont populaires. Uber utilise Jaeger pour tracer 2+ milliards de requêtes par jour et identifier les goulots d'étranglement.
Le rate limiting limite le nombre de requêtes qu'un client peut faire. Les stratégies communes :
Token Bucket Algorithm
Chaque utilisateur a un "seau" de tokens. Chaque requête consomme un token. Le seau se remplit à vitesse constante.
Quand le seau est vide, requêtes rejetées.
Sliding Window
Compte les requêtes dans une fenêtre glissante. Plus précis que fixed window mais plus coûteux en mémoire.
Distributed Rate Limiting
Avec plusieurs serveurs, le rate limiting doit être partagé. Redis est parfait pour ça : chaque serveur incrémente un compteur partagé.
Twitter limite à 300 tweets/3h et 1000 follows/jour. GitHub API : 5000 requêtes/heure pour les utilisateurs authentifiés.
Si on me demandais de le résumé en deux mots :
Recherche de compromis...
Si... je devais en rajouter 2 autres?
Qu'on aligne aux objectifs métiers !
Chaque décision — cohérence vs disponibilité, monolithe vs microservices, SQL vs NoSQL, synchone vs asynchrone — doit être guidée par des contraintes réelles: volume, criticité, SLA, coût, équipe, et complexité opérationnelle.
Retenez les principes clés:
• Commencer simple, mesurer, puis évoluer: un monolithe modulaire bien conçu vous emmène très loin avant d’extraire des services.
• Concevoir pour l’échec: réplication, circuit breaker, retries, bulkheads, health checks et autoscaling sont non négociables à l’échelle.
• Optimiser là où ça compte: cache, CDN, partitionnement, sharding et queues pour découpler et réduire la latence perçue.
• Observer en continu: métriques (P50/P95/P99), logs structurés et tracing distribué pour détecter, diagnostiquer et itérer rapidement.
• Sécurité en profondeur: authentification, autorisation et protections en couches dès le début.
En pratique, dessinez une architecture que vous pouvez expliquer en 5 minutes, instrumentez-la, testez sa charge, puis faites évoluer progressivement les composants qui deviennent des goulots d’étranglement. Le bon design est celui qui répond aujourd’hui à vos besoins, tout en laissant une voie claire pour demain.
Article par B.ERRAJI, consultant data OSSIA - SONATE

Chaque fin de mois retrouvez une sélection de l'info du monde de l'IT et de la tech !









