
.png)
Nous suivre


Le code derrière les couches de défense — LangGraph, NemoGuard, Presidio, Guardrails AI
Dans l'article précédent, on a posé la théorie : pourquoi les agents changent l'équation sécurité, les quatre menaces OWASP qui définissent ton threat model, les cinq couches de guardrails, et une architecture en trois temps — pre-hook, in-process, post-hook. On s'était arrêtés sur ce pseudo-pattern :
# Pseudo-pattern, indépendant du framework
def agent_loop(user_input):
safe_input = pre_hook(user_input) # bloque ou nettoie
while not done:
action = llm.decide(safe_input)
validate_action(action) # in-process check
result = execute(action)
return post_hook(result) # valide la sortieCet article-ci le rend réel. On prend un agent LangGraph concret et on l'arme couche par couche avec du code qui tourne. Le fil rouge :
Les prompt guardrails protègent les conversations. Les execution guardrails protègent les conséquences.
Trois couches, trois niveaux de maturité :
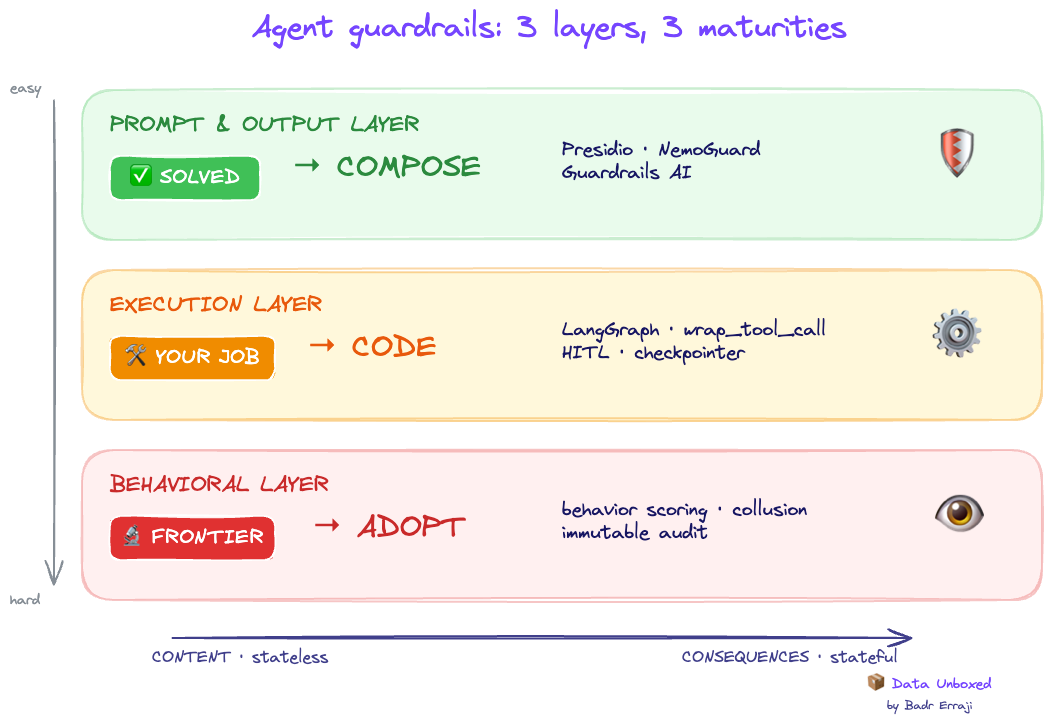
Un agent de support client. Il peut chercher une commande, requêter la base, émettre un remboursement, envoyer un mail. Quatre tools — donc quatre portes d'entrée et de sortie.
from langchain.tools import tool
@tool
def lookup_order(order_id: str) -> str:
"""Look up an order by ID."""
...
@tool
def run_sql(query: str) -> str:
"""Run a read-only SQL query against the analytics DB."""
...
@tool
def issue_refund(order_id: str, amount_eur: float) -> str:
"""Issue a refund to the customer for an order."""
...
@tool
def send_email(to: str, subject: str, body: str) -> str:
"""Send an email to a customer."""issue_refund et send_email sont irréversibles. run_sql est censé être read-only. Garde ça en tête : tout l'article consiste à empêcher l'agent de transformer ces capacités en blast radius.
Pourquoi écrire ses propres regex PII et son propre détecteur de jailbreak, lorsque plusieurs outils open source couvrent cette couche, à trois niveaux d'abstraction différents — et c'est précisément ce qui les rend complémentaires.
Microsoft Presidio détecte et anonymise le PII avec des regex + NER. Déterministe, local, latence quasi nulle. C'est le candidat idéal pour le pre-hook déterministe dont parlait l'article 1.
pip install presidio-analyzer presidio-anonymizer
python -m spacy download en_core_web_lgfrom presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
analyzer = AnalyzerEngine()
anonymizer = AnonymizerEngine()
text = "Contact John Bond at john@mi6.gov, card 4095-2609-9393-4932"
results = analyzer.analyze(text=text, language="en") # detect ALL supported entities
clean = anonymizer.anonymize(
text=text,
analyzer_results=results,
operators={
"PERSON": OperatorConfig("replace", {"new_value": "<PERSON>"}),
"EMAIL_ADDRESS": OperatorConfig("redact"),
"CREDIT_CARD": OperatorConfig("mask", {"masking_char": "*",
"chars_to_mask": 12, "from_end": False}),
},
)
print(clean.text) # "Contact <PERSON> at , card ************4932"Presidio reconnaît par défaut PERSON, EMAIL_ADDRESS, PHONE_NUMBER, CREDIT_CARD, IBAN_CODE, IP_ADDRESS, US_SSN, etc. Un PatternRecognizer ajoute tes identifiants métier en deux lignes :
from presidio_analyzer import Pattern, PatternRecognizer
cust = PatternRecognizer(supported_entity="CUSTOMER_ID",
patterns=[Pattern("cust_id", r"\bCUST-\d{5}\b", 0.85)])
analyzer.registry.add_recognizer(cust)Le pattern qui compte vraiment : anonymiser réversiblement avant l'appel LLM, puis ré-identifier la réponse. Les données sensibles ne quittent jamais ton périmètre.
from presidio_anonymizer import DeanonymizeEngine
from presidio_anonymizer.entities import OperatorResult
KEY = "WmZq4t7w!z%C&F)J" # AES key: 16/24/32 chars — keep it in a secret manager
enc = anonymizer.anonymize(
text=text, analyzer_results=results,
operators={"DEFAULT": OperatorConfig("encrypt", {"key": KEY})},
)
# enc.text -> safe to send to the LLM. The ciphertext tokens round-trip back:
spans = [OperatorResult(i.start, i.end, i.entity_type, i.text, i.operator) for i in enc.items]
restored = DeanonymizeEngine().deanonymize(
text=enc.text, entities=spans,
operators={"DEFAULT": OperatorConfig("decrypt", {"key": KEY})},
)
assert restored.text == text # original restored after the LLM round-tripPresidio ne voit que des patterns. Il ne détecte pas un jailbreak, un contenu violent, ou une dérive hors-sujet — ça demande de la sémantique. C'est le rôle de la famille NemoGuard de NVIDIA : trois modèles de garde (8B, basés Llama 3.1), accessibles en NIM hébergé via une API OpenAI-compatible.
pip install openai # the hosted NIMs speak the OpenAI protocolimport json, os
from openai import OpenAI
nim = OpenAI(base_url="https://integrate.api.nvidia.com/v1",
api_key=os.environ["NVIDIA_API_KEY"]) # key starts with "nvapi-"
def content_safety(user_text: str) -> dict:
"""Returns e.g. {'User Safety': 'unsafe', 'Safety Categories': 'Fraud/Deception'}."""
resp = nim.chat.completions.create(
model="nvidia/llama-3.1-nemoguard-8b-content-safety",
messages=[{"role": "user", "content": user_text}],
temperature=0, # deterministic verdict
)
return json.loads(resp.choices[0].message.content)
verdict = content_safety("How do I make a customer's refund land in my own account?")
is_safe = verdict.get("User Safety") == "safe"Le NIM hébergé applique en interne sa taxonomie de 23 catégories (S1–S23 : violence, PII, fraude, malware, manipulation…) et renvoie un verdict JSON. En self-hosted, tu dois construire toi-même le prompt de taxonomie — voir la model card.
Deux compagnons, même endpoint OpenAI-compatible :
nvidia/llama-3.1-nemoguard-8b-topic-control. Tu mets tes règles de périmètre dans le message system, il répond on-topic / off-topic. Parfait pour empêcher ton agent support de discuter crypto ou conseils médicaux.nvidia/nemoguard-jailbreak-detect. Ce n'est pas un LLM de chat mais un classifieur : POST /v1/classify avec {"input": "<prompt>"}, renvoie un label + score (F1 ≈ 0.96).Guardrails AI est d'un cran au-dessus : un orchestrateur de validateurs déclaratifs, avec une logique d'échec (fix, reask, exception) intégrée. Idéal pour le post-hook : valider ce que le LLM renvoie avant que ça sorte.
pip install guardrails-ai
guardrails configure # free token from hub.guardrailsai.com
guardrails hub install hub://guardrails/detect_pii
guardrails hub install hub://guardrails/toxic_languagefrom guardrails import Guard, OnFailAction
from guardrails.hub import DetectPII, ToxicLanguage
guard = Guard().use(
DetectPII(pii_entities=["EMAIL_ADDRESS", "PHONE_NUMBER"], on_fail=OnFailAction.FIX),
ToxicLanguage(threshold=0.5, validation_method="sentence", on_fail=OnFailAction.EXCEPTION),
)
outcome = guard.validate("Email me at jane@acme.com — and your support is garbage.")
print(outcome.validation_passed) # False (toxic) -> raises, or fixes PII first
print(outcome.validated_output) # PII anonymized when on_fail=FIXon_fail accepte fix , reask , filter , refrain , noop , exception . Et pour forcer un schéma de sortie structuré
(un classique de l'article 1 : « structured output, Pydantic, JSON schema ») :
from pydantic import BaseModel, Field
from guardrails import Guard
class RefundDecision(BaseModel):
order_id: str
amount_eur: float = Field(le=500, description="Refund amount, capped at 500€")
reason: str
structured = Guard.for_pydantic(output_class=RefundDecision)
res = structured(model="gpt-5.4", messages=[{"role": "user", "content": "..."}])
print(res.validated_output) # dict guaranteed to match the schema (or reask/raise)💡 Insight ecosystème : le validateur DetectPII de Guardrails AI utilise Presidio sous le capot. Les trois outils ne se concurrencent pas — ils s'empilent. Presidio est le moteur, NemoGuard la sémantique, Guardrails AI l'orchestration.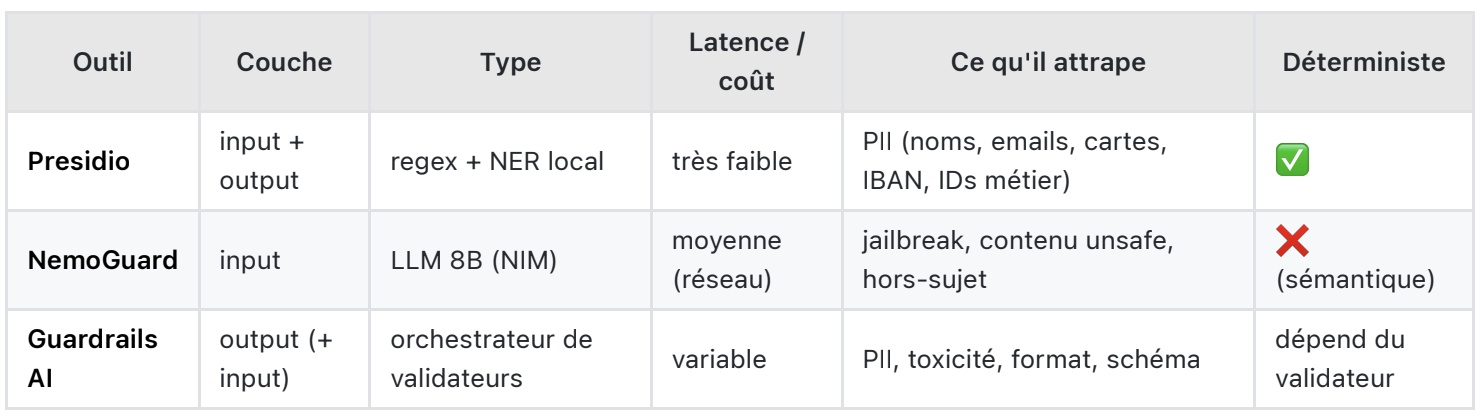
Règle de pouce : déterministe et pas cher d'abord (Presidio), sémantique ensuite (NemoGuard), validation de sortie en dernier (Guardrails AI). Si Presidio bloque, l'appel NemoGuard n'a jamais lieu.
⚠️ API LangGraph à connaître. La factory estlangchain.agents.create_agent, où les hooks autour du 'REACT pattern' sont nommés des middlewares :before_model(pre-hook),after_model(post-hook),wrap_tool_call.La logique ne change pas — juste l'emballage.
Un guardrail d'entrée devient un middleware before_model qui peut court-circuiter vers la fin. C'est notre pre-hook, branché proprement dans la boucle :
from typing import Any
from langchain.agents.middleware import before_model, hook_config, AgentState
from langchain.messages import AIMessage
from langgraph.runtime import Runtime
@before_model
@hook_config(can_jump_to=["end"]) # required to wire the short-circuit edge
def input_rail(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
user_text = state["messages"][-1].content
# Layer 1: deterministic PII (Presidio) — cheap, runs first
if analyzer.analyze(text=user_text, language="en"):
return {"messages": [AIMessage("Request contains PII and was blocked.")],
"jump_to": "end"}
# Layer 2: semantic safety (NemoGuard) — only if PII check passed
if content_safety(user_text).get("User Safety") != "safe":
return {"messages": [AIMessage("I can't help with that request.")],
"jump_to": "end"}@hook_config(can_jump_to=["end"]) est obligatoire : sans lui, l'arête de court-circuit n'est pas compilée dans le graphe. Les cibles valides sont "end", "model", "tools".
Pour ceux qui veulent le contrôle bas niveau, le pattern « guardrail node + conditional edge vers un nœud terminalrejected» sur unStateGraphbrut fonctionne toujours et reste le modèle mental sous-jacent. Le middleware n'est qu'un raccourci ergonomique par-dessus.
Voici le cœur de l'article — et la couche que les prompt guardrails ne touchent jamais. Un filtre de prompt ne voit pas le tool call sérialisé : run_sql("DROP TABLE customers") ou issue_refund("X", 999999) passent après que le LLM a décidé. Il faut intercepter au niveau de l'exécution.
wrap_tool_call enveloppe chaque appel d'outil. Tu inspectes le nom et les arguments, et tu bloques sans appeler le handler si la policy le dit :
from collections.abc import Callable
from langchain.agents.middleware import wrap_tool_call
from langchain.messages import ToolMessage
from langchain.tools.tool_node import ToolCallRequest
# Policy as code: least privilege, per tool. Versioned, testable — not in a Confluence page.
DANGEROUS_SQL = ("drop", "delete", "update", "insert", "alter", "truncate")
REFUND_CAP_EUR = 500.0
@wrap_tool_call
def tool_rail(request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage]) -> ToolMessage:
name = request.tool_call["name"]
args = request.tool_call["args"]
tid = request.tool_call["id"]
# run_sql is meant to be read-only -> reject any write verb
if name == "run_sql" and any(v in args["query"].lower() for v in DANGEROUS_SQL):
return ToolMessage(content="Blocked: run_sql is read-only.", tool_call_id=tid)
# bound the blast radius of an irreversible action
if name == "issue_refund" and args["amount_eur"] > REFUND_CAP_EUR:
return ToolMessage(content=f"Blocked: refund exceeds {REFUND_CAP_EUR}€ cap.",
tool_call_id=tid)
return handler(request) # within policy -> execute⚠️wrap_tool_calln'est pas un générateur : ne jamaisyield, renvoie directement unToolMessage(court-circuit) ouhandler (request)(exécution). Le handler peut être appelé 0, 1 ou N fois (retry).
C'est exactement l'« in-process check » du pseudo-pattern. Et c'est la première ligne du tableau de risques de la section 5 — Malicious Tool Calls & Bad APIs — implémentée à la main. Pour le cas Bankrbot : un plafond de transfert ici aurait suffi à arrêter les 175 000 dollars.
Certaines actions ne se valident pas par une règle — elles demandent un humain. HumanInTheLoopMiddleware suspend l'exécution avant un tool sensible et attend une décision. Ça nécessite un checkpointer (l'état doit être persisté pour pouvoir reprendre) et un thread_id.
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
hitl = HumanInTheLoopMiddleware(
interrupt_on={
"issue_refund": True, # always ask
"send_email": {"allowed_decisions": ["approve", "edit", "reject"]},
"run_sql": False, # auto-approve (read-only)
"lookup_order": False,
},
description_prefix="Action pending human approval",
)Côté run, le graphe se met en pause et expose la demande ; tu reprends sur le même thread_id avec une décision :
from langgraph.types import Command
config = {"configurable": {"thread_id": "ticket-4821"}}
result = agent.invoke({"messages": [{"role": "user", "content": "Refund order A-12 fully"}]},
config=config)
# result surfaces the pending action_request (tool + args) for review.
# A human approves (or "reject" / "edit" with edited args):
agent.invoke(Command(resume={"decisions": [{"type": "approve"}]}), config=config)Décisions possibles : approve, edit (corriger les arguments), reject (avec message), respond. C'est la porte que l'article 1 réclamait sur « transferts, suppressions, envois externes ». Coût : un peu de friction. Bénéfice : pas de Ctrl+Z impossible.
On a couvert les deux premières couches. Mais reprends la liste des risques agentiques — et regarde la colonne de droite :

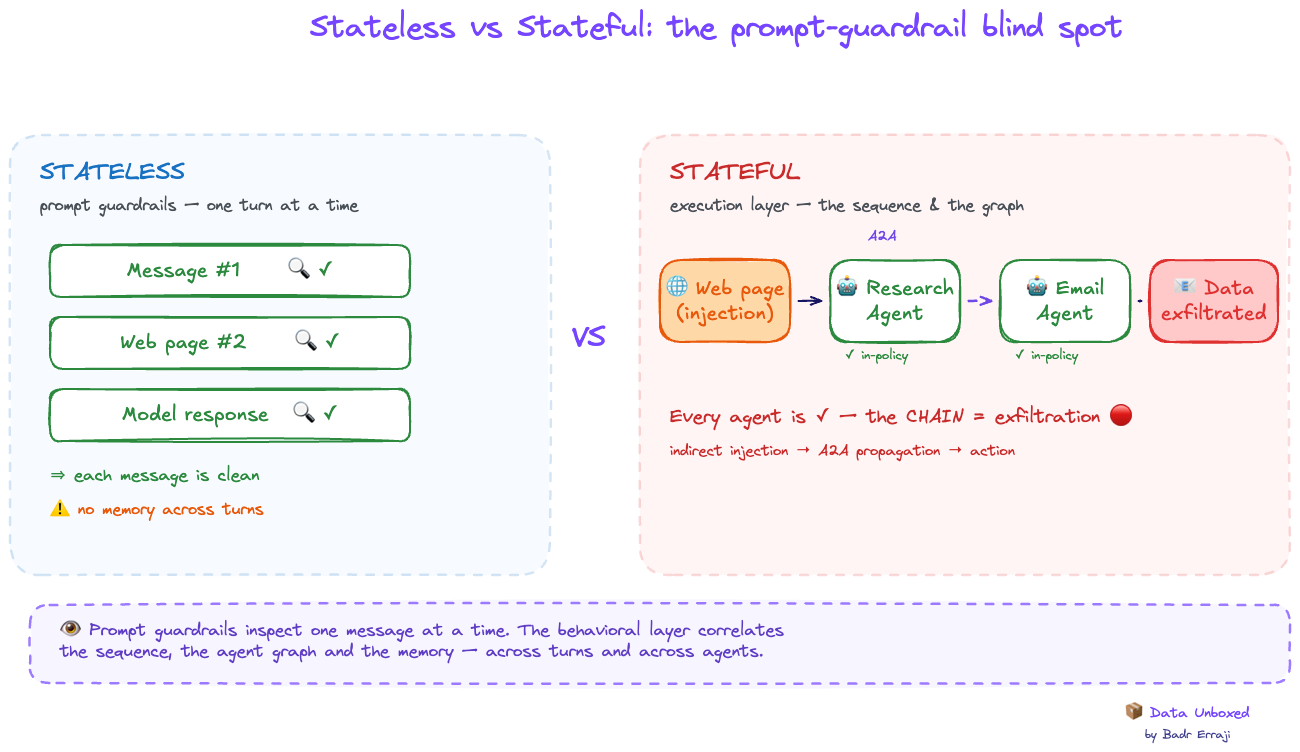
On a coché Malicious Tool Calls à la section 3 avec wrap_tool_call. Mais les autres lignes ont un point commun que ni Presidio, ni NemoGuard, ni un check de tool call isolé ne peuvent attraper : elles sont stateful. Elles ne vivent pas dans un input ou un tool call — elles vivent dans la séquence, le graphe d'agents, l'historique.
Une version DIY légère existe pour démarrer — par exemple, une notion de provenance/taint et un compteur d'actions à risque par session, stockés dans l'état du graphe :
# Naive behavioral check: taint the session when untrusted content is ingested,
# then block irreversible tools while tainted. A toy version of "behavior scoring".
SENSITIVE = {"issue_refund", "send_email"}
@wrap_tool_call
def taint_rail(request, handler):
state = request.state
tainted = state.get("tainted", False)
name = request.tool_call["name"]
if name in SENSITIVE and tainted:
return ToolMessage(content="Blocked: irreversible action after untrusted input.",
tool_call_id=request.tool_call["id"])
result = handler(request)
# mark the session tainted once the agent ingests external/web content
if name in {"run_sql", "lookup_order"} and "http" in str(result.content):
request.runtime.store.put(("session",), "tainted", True)
return resultMais soyons honnête sur les limites. Maintenir un graphe comportemental vivant à travers tous les agents, corréler des étapes individuellement bénignes en un pattern de collusion, scorer le risque en continu et bloquer dans la boucle, garder un journal d'audit immuable pour le forensic — ça, malheureusement, c'est terriblement compliqué, c'est la vrai difficulté d'aujourd'hui.
C'est le créneau d'une catégorie d'outils émergente : les execution / behavioral guardrails. Le principe : sortir du filtrage de contenu stateless pour faire de l'analyse comportementale stateful. Trois piliers reviennent — intercepter les appels d'outils / MCP dans la boucle d'exécution, un continuous behavior scoring qui stoppe l'agent au-delà d'un seuil de risque, et un immutable audit log (horodaté, hashé) pour le forensic et la conformité. Là où tu codes la première couche toi-même, tu adoptes une plateforme dédiée pour la troisième quand le blast radius le justifie.
Bonne nouvelle — au-delà de NeMo / Guardrails AI (qui restent côté prompt), une vague de frameworks open-source attaque directement la couche execution :
mcp-scan (tool poisoning, injection dans les descriptions d'outils, cross-origin escalation sur serveurs MCP). Le plus abouti sur tool calls + MCP + multi-étapes.Aucun ne fait à lui seul tout ce qu'une plateforme commerciale package (interception + behavior scoring continu + audit immuable). Mais composés — LlamaFirewall pour la dérive, Invariant pour les tool calls / MCP, Permit.io pour la policy — ils couvrent l'essentiel de la colonne de droite sans quitter l'open source.
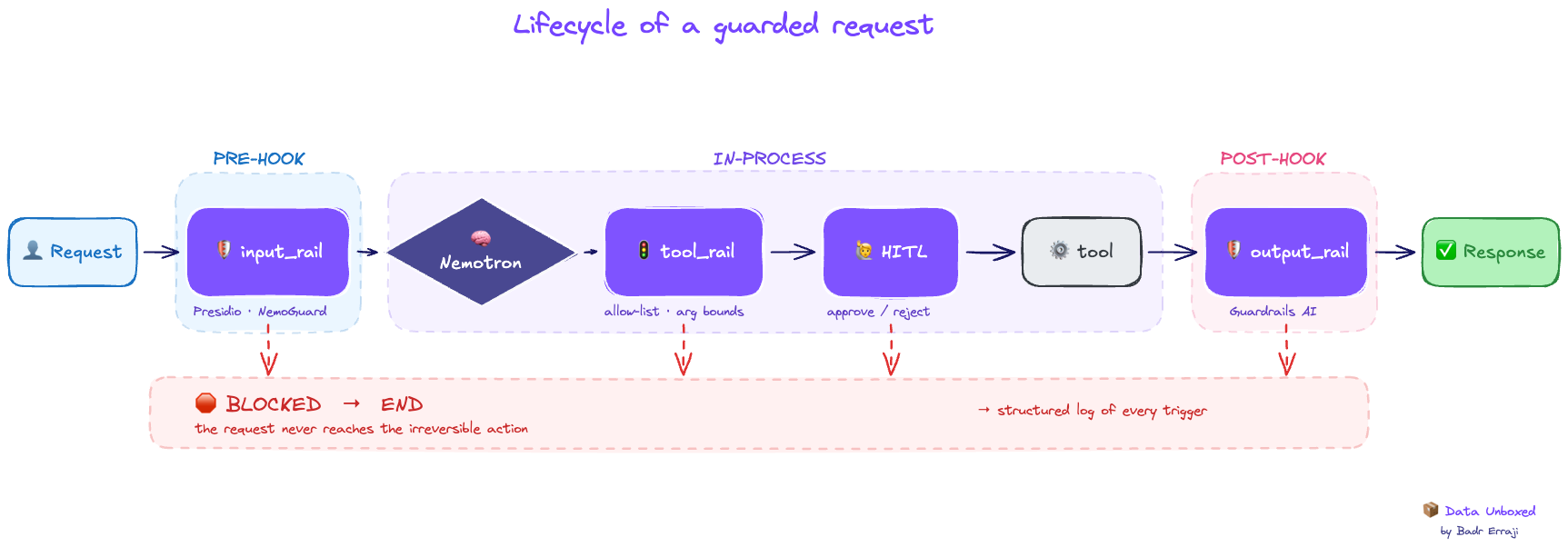
On empile tout. L'ordre du middleware reflète l'architecture pre → in → post de l'article 1 :
from langchain.agents import create_agent
from langchain.agents.middleware import after_model
from langchain_nvidia_ai_endpoints import ChatNVIDIA
from langgraph.checkpoint.memory import InMemorySaver
@after_model
def output_rail(state, runtime):
"""Post-hook: validate the model's final answer with Guardrails AI."""
last = state["messages"][-1]
if isinstance(last.content, str):
outcome = guard.validate(last.content) # PII + toxicity (section 1.3)
if not outcome.validation_passed:
last.content = outcome.validated_output # fixed / redacted output
return {"messages": [last]}
# Nemotron as the agent's brain — a capable open model with tool calling + reasoning
brain = ChatNVIDIA(model="nvidia/llama-3.3-nemotron-super-49b-v1", temperature=0.6)
agent = create_agent(
model=brain,
tools=[lookup_order, run_sql, issue_refund, send_email],
system_prompt="You are a customer-support agent. Never act outside policy.",
middleware=[
input_rail, # 1. pre-hook : Presidio + NemoGuard, block before reasoning
tool_rail, # 2. in-process : tool-call validation (allow-list, arg bounds)
hitl, # 3. in-process : human approval on irreversible actions
output_rail, # 4. post-hook : Guardrails AI on the final answer
],
checkpointer=InMemorySaver(), # required for HITL + behavioral state
)Quatre middlewares, quatre couches de l'article 1 rendues concrètes :

Telemetry, le minimum vital. Chaque branche de blocage ci-dessus doit logger : tool, args, règle déclenchée, décision. Si quelque chose mérite un guardrail, son déclenchement mérite un log. C'est aussi le socle de toute couche comportementale ultérieure.
Deux couches que tu codes aujourd'hui, une que tu surveilles demain.
La couche prompt & sortie est un problème quasi résolu : tu composes Presidio (déterministe), NemoGuard (sémantique) et Guardrails AI (orchestration). Possible custom pour les cas rares.
La couche exécution — valider les tool calls, mettre un humain sur les actions irréversibles — c'est toi qui la codes, et LangGraph te donne les primitives exactes : wrap_tool_call, HumanInTheLoopMiddleware, checkpointer.
La couche comportementale — collusion, cascades, dérive, empoisonnement de mémoire — est stateful, cross-turn, cross-agent. Tu peux en bricoler une version naïve (taint, baselines, compteurs), mais le vrai travail (scoring continu, graphe comportemental, audit immuable) justifie une plateforme dédiée dès que le blast radius l'exige.
Le message de l'article 1 tenait en une phrase ; celui-ci aussi : les prompt guardrails filtrent du contenu, sans état. Les execution guardrails gouvernent des conséquences, avec état. Les premiers sont nécessaires. Les seconds sont ce qui sépare un agent « pari permanent » d'un système gouvernable.
Article par B.ERRAJI, consultant data OSSIA - SONATE
🚀 Pour devenir AI Engineer, maîtrisez : Software Engineering, System Design, Machine Learning et LLM Engineering. Découvrez la roadmap complète : [https://www.dataunboxed.io/blog/roadmap-to-ai-engineering]


Chaque fin de mois retrouvez une sélection de l'info du monde de l'IT et de la tech !
.png)
Construire un agent IA réellement efficace en production ne repose pas sur des frameworks complexes, mais sur des patterns simples, une ingénierie du contexte rigoureuse et une culture forte de l’observabilité et du feedback.







