

Nous suivre


CECI n'est pas une publicité pour Databricks.
J'adore utiliser Databricks. Elle m'a rendu les choses bien plus simples en termes de data.
Que ce soit en data engineering, où l'expérience dev est vraiment super fluide, ou en data science avec un outil devenuune référence dans le domaine du ML/MLOps : MLflow, nativement intégré à la plateforme.
Toutes les problématiques rencontrées dans le monde de la data ont été pensées aux petits oignons et rendues superefficaces.
Alors oui, cela peut paraître cher si on regarde le pricing tout seul. Leur marketing peut sembler très agressif et « àl'américaine » — surtout pour nous en France. Mais la valeur ajoutée en vaut la chandelle.
Pour ceux qui recherchent une expérience toujours très proche du "Production Ready", quitte à payer un premium pourcette tranquillité : Databricks est un pari sûr.
Et c'est pour ça que j'avais hâte de voir ce qu'ils allaient nous sortir autour des LLMs et de l'agentique.
Ça a un peu tardé. Mais petit à petit, on voit émerger leurs produits agents. Et comme pour l'expérience Data, ças'annonce super intéressant : d'une part Mosaic AI Agent Framework (le framework de développement) et de l'autre Agent Bricks (plus orienté interface et productisation rapide).
Est-ce que ça sera une raison de tout quitter pour construire son agent avec leur framework ?
NON, vraiment pas. Mais si on est déjà très lié à Databricks ou qu'on veut un environnement data unifié qui enforce lesrègles de sécurité et de gouvernance, alors c'est un point sérieux à considérer.C'est d'ailleurs sur ce point qu'on va commencer.
Databricks ne se contente plus de proposer des features GenAI en surcouche. La stratégie est désormais clairementorientée vers les systèmes agentiques : des agents multi-modèles, capables d'utiliser des outils, de percevoir,raisonner et agir sur des workflows d'entreprise — et non plus simplement répondre à des prompts.
Leur rapport "State of AI Agents" et leurs guides stratégiques récents positionnent l'IA agentique comme la phasesuivante, après les chatbots simples, avec un focus sur la planification, l'autonomie et l'amélioration continue.
Ce repositionnement est important : il place Databricks dans le même espace narratif que les OpenAI Agents,LangGraph/LangChain et les autres stacks agent-centric. Sauf que Databricks arrive avec un avantage que les autresn'ont pas : la data.
Le gros différenciateur, c'est que les capacités agents de Databricks ne sont pas un SaaS séparé : elles sontconstruites directement dans le Lakehouse / la "Data Intelligence Platform".
Concrètement, ça veut dire :

En comparaison, avec les frameworks tool-centric (LangChain, CrewAI…), la data, l'infra et la gouvernance sontgénéralement boulonnées après coup. Ici, c'est natif.
C'est un peu comme si on construisait un agent directement dans son entrepôt de données, plutôt que de connecter unagent externe à ses données via des API bricolées.
Databricks a transformé les "agents" de simples patterns de code en features produit de premier ordre.
Annoncé mi-2025, Agent Bricks est un outil UI-driven qui automatise le cycle de vie des agents d'entreprise : création,choix d'architecture, évaluation, optimisation coût/qualité, et promotion en production.
Leur gamme d'agents natifs :
Pour avoir des agents production-ready très rapidement, c'est redoutable.
Pour aller plus loin dans la customisation :
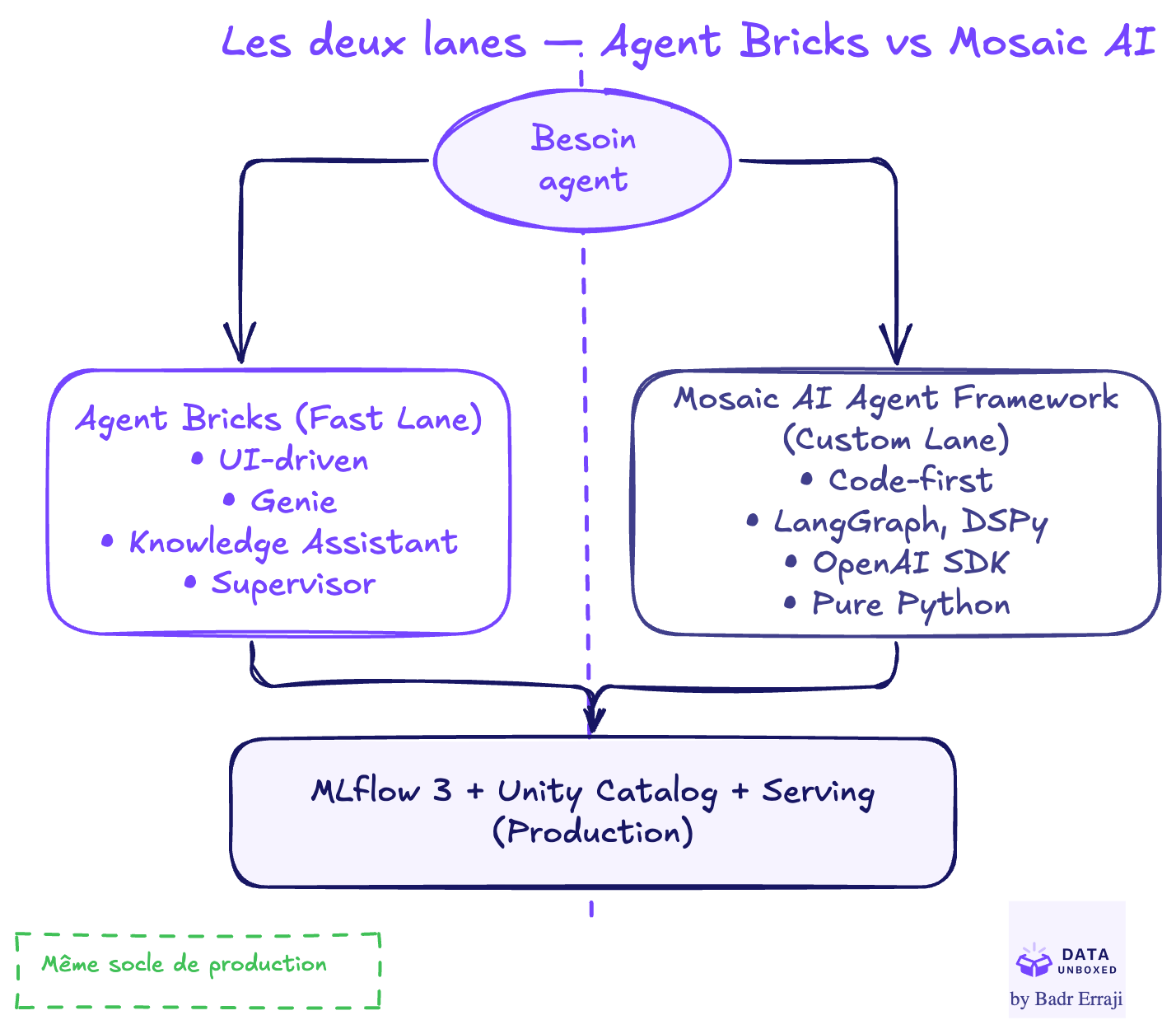
En résumé : Agent Bricks pour le "fast lane", Mosaic AI Agent Framework pour le "custom lane". Les deux convergentvers le même objectif : des agents en production, gouvernés et monitorés.
C'est peut-être le point le plus sous-estimé et pourtant le plus stratégique.
MLflow 3 a été repensé et adapté aux agents. L'évaluation n'est plus un "nice to have" : c'est le contrat de comportement de l'agent.
Databricks a mis un focus majeur sur :
DSPy — Une initiative Databricks souvent oubliée
Rappelons aussi que DSPy est une initiative Databricks. Cette librairie permet d'optimiser automatiquement les prompts en se basant sur des datasets de cas d'usage — probablement alimentés par le tracing et les annotationscollectés en production. C'est le chaînon manquant entre l'évaluation et l'amélioration continue.
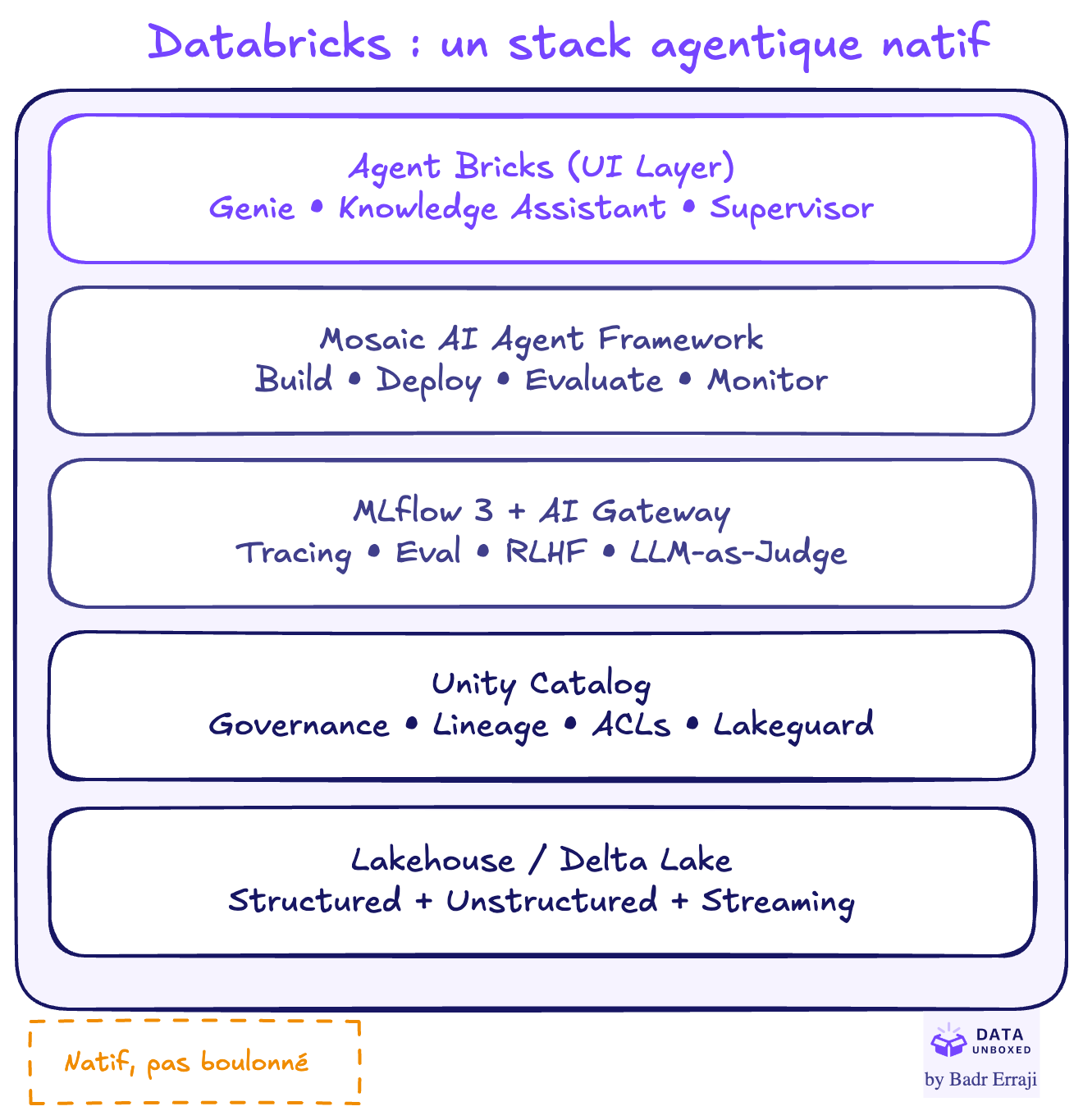
L'idée de fond : les évaluations comme boucle continue (pas un test one-shot), et comme outil de gouvernance (Unity Catalog + Lakeguard + AI Gateway + MLflow tracing = audit trail complet des actions de l'agent).
Databricks ne cherche pas à remplacer l'écosystème d'orchestration d'agents. Ils cherchent à l'héberger etl'opérationnaliser.
En d'autres termes, Databricks ne rattrape pas son retard en gagnant la guerre des frameworks, mais en devenantle plan de production et de données par défaut pour ces frameworks.
C'est probablement LA raison pour laquelle Databricks peut rattraper rapidement son retard dans les entreprises, mêmesi les frameworks developer-first innovent plus vite sur les features :
Pour les industries régulées (banque, santé, assurance…), c'est un argument massif.
Pour ceux qui doutent encore que Databricks est crédible dans l'agentique :
On passe clairement du stade "en retard" au stade "pair crédible" dans l'écosystème agentique.
Databricks ne rattrape pas son retard en construisant les agents les plus flashy. Elle le rattrape en possédant la couchedata, gouvernance et production où l'IA agentique sérieuse doit vivre.
C'est une remontada silencieuse mais redoutablement efficace : pendant que tout le monde se bat sur les frameworks etles démos, Databricks construit le socle sur lequel ces agents devront tourner en production.
Et si vous êtes déjà dans l'écosystème Databricks ? Vous avez probablement déjà tout ce qu'il faut pour commencer.
Article par B.ERRAJI, consultant data OSSIA - SONATE



La GenAI ne remplace pas le data engineering, elle le redéfinit — et rend votre rôle plus stratégique que jamais.







