
.png)
Construire un agent IA réellement efficace en production ne repose pas sur des frameworks complexes, mais sur des patterns simples, une ingénierie du contexte rigoureuse et une culture forte de l’observabilité et du feedback.
Nous suivre


Les agents IA représentent une évolution naturelle & majeure dans l'utilisation des LLMs. C'est une composante grandement "software" qu'on met autour des modèle de GenAI (LLMs, VLM, etc.). Mais construire un agent qui fonctionne réellement en production demande bien plus que d'enchaîner des appels API. Toute une ingénieurie de ces nouveaux systèmes IA stochastiques par nature. Les implémentations les plus réussies reposent sur des patterns simples et composables plutôt que sur des frameworks complexes.
Bon, si vous avez déjà utilisé chatGPT ou autre (enfin je l'espère pour vous !), Alors vous savez qu'un des gros points faibles des LLMs est leur capacité à générer des hallucinations. de manière complètement crédible et cohérente.Souvent, Il faut un regard critique et avisé sur le sujet/domaine pour les détecter.
c'est pour ça qu'une des dimensions principales / challenges majeurs de l'IA agentique est de minimiser les hallucinations. Car s'il n'y a pas de confiance dans l'éxecution d'une tâche, alors l'agent ne peut pas être utilisé.
Un agent est une pièce logicielle qui utilise un LLM comme moteur de raisonnement pour exécuter des fonctions.
On distingue deux architectures principales :

Chacun a ses avantages et inconvénients.
Il faut impérativement garder en tête que dans le cas d'un agent qui planifie lui même ses tâches et ses nexts steps:
Si on a un taux d'erreur de 1% par step, les probabilités composés vont très vite passer à 100% à la 72ème step de raisonnement.
Mon point ici est que sur un nombre de steps de raisonnement très élevée, un taux d'erreur même aussi faible que 1% par step peut très vite devenir critique.
Les solutions sont :
💡 Règle d'or : Commencez par la solution la plus simple. N'ajoutez de la complexité que si elle améliore mesurément les résultats.
Il est possible aussi de rajouter des guardsrails / checks pour vérifier la validité des actions / nexts steps. mais cela augmenter drastiquement les coûts de l'agent en termes de tokens consommés mais également en termes de latence.
Les patterns suivants constituent la boîte à outils de tout développeur d'agents :
Décompose une tâche en étapes séquentielles. Chaque appel LLM traite la sortie du précédent.
Exemple : Générer un texte marketing, puis générer les images associées, générer les métadata pour le référencement SEO, etc.

Classifie l'input et le dirige vers un traitement spécialisé.
Exemple : Router les questions simples vers un modèle léger, les complexes vers un modèle avancé.
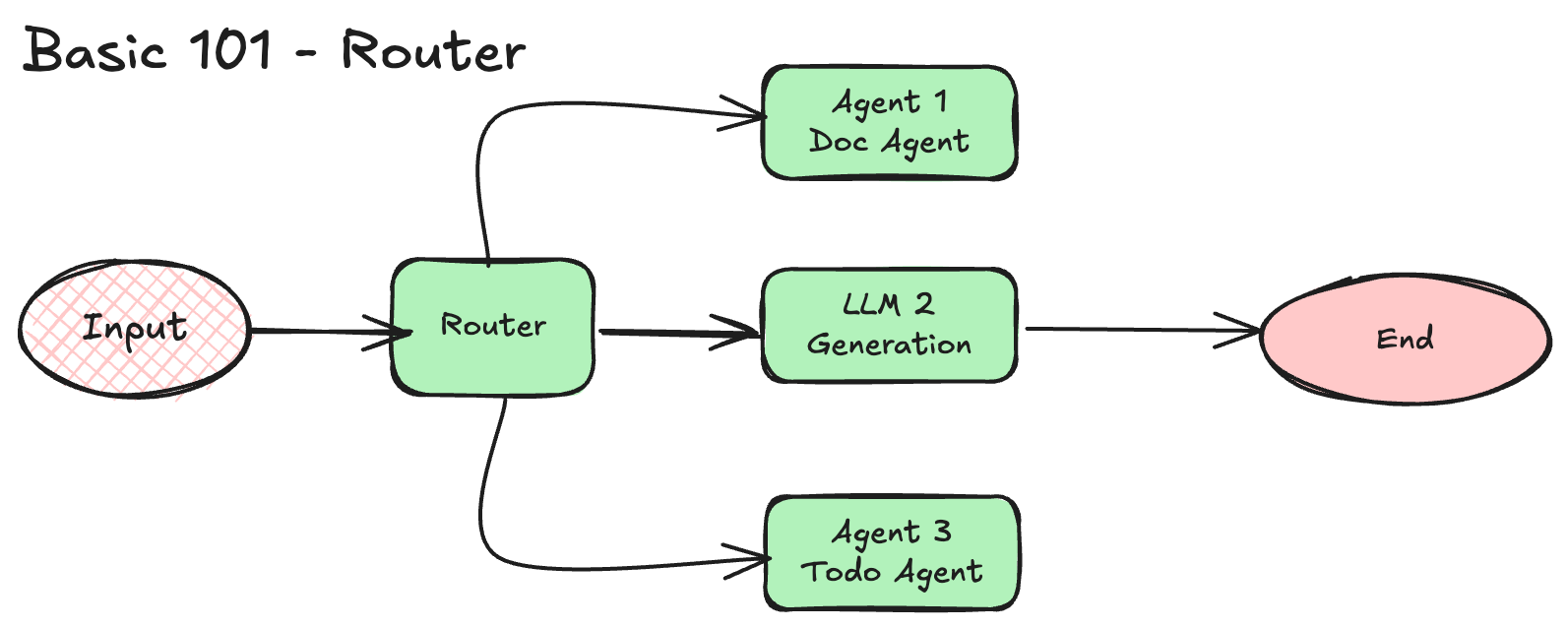
Exécute des sous-tâches simultanément (sectioning) ou multiple fois pour diversifier les outputs (voting).
Exemple : Évaluer du code avec plusieurs prompts spécialisés en parallèle.
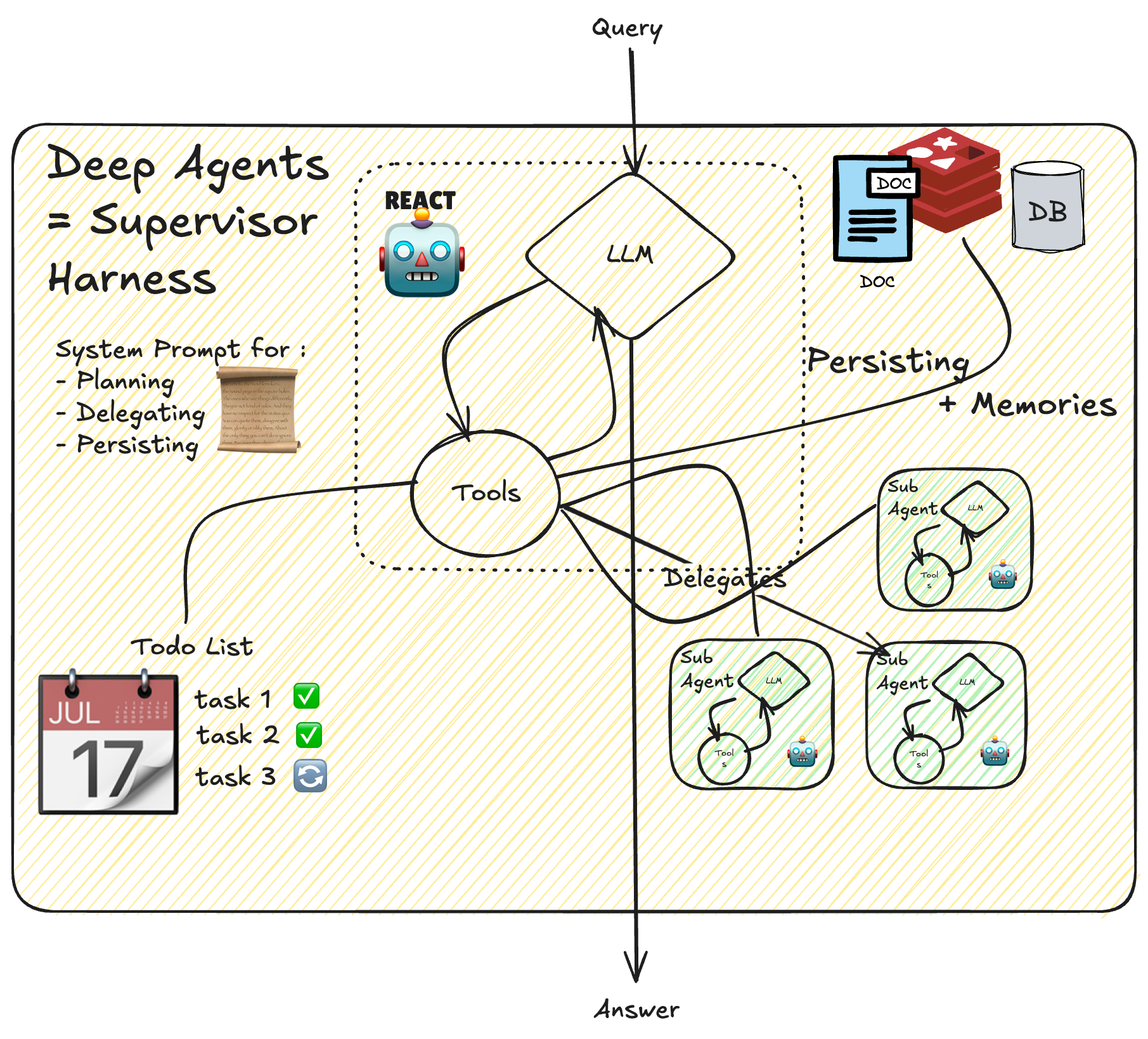
Un LLM central décompose dynamiquement les tâches et délègue à des workers.
Exemple : Agent de code modifiant plusieurs fichiers selon le contexte.
Un LLM génère, un autre évalue et donne du feedback en boucle.
Exemple : Génération d'une synthèse de texte avec raffinements itératifs.
Le pattern ReAct est le fondement de la plupart des agents autonomes. Il structure l'exécution en une boucle itérative :Observation → Réflexion → Action → Observation → ...

À chaque étape, l'agent :
1. Observe le résultat de l'action précédente (ou l'input initial)
2. Raisonne sur ce qu'il a appris et ce qu'il doit faire ensuite
3. Agit en appelant un outil ou en générant une réponse
Ce pattern permet à l'agent de s'auto-corriger en cours de route grâce au feedback de l'environnement (résultats d'appels d'outils, exécution de code, etc.). C'est ce qui distingue un agent d'une simple chaîne de prompts : la capacité à ajuster sa trajectoire en fonction de la réalité du terrain.
⚠️ Point de vigilance : Plus l'agent est autonome, plus le risque d'erreurs composées augmente. Prévoyez des conditions d'arrêt (nombre max d'itérations) et des checkpoints pour validation humaine.
Exemple : Un agent de code qui exécute des tests, analyse les erreurs, corrige son code, et ré-exécute jusqu'à ce que les tests passent.
Un LLM central décompose dynamiquement les tâches et délègue à des workers.
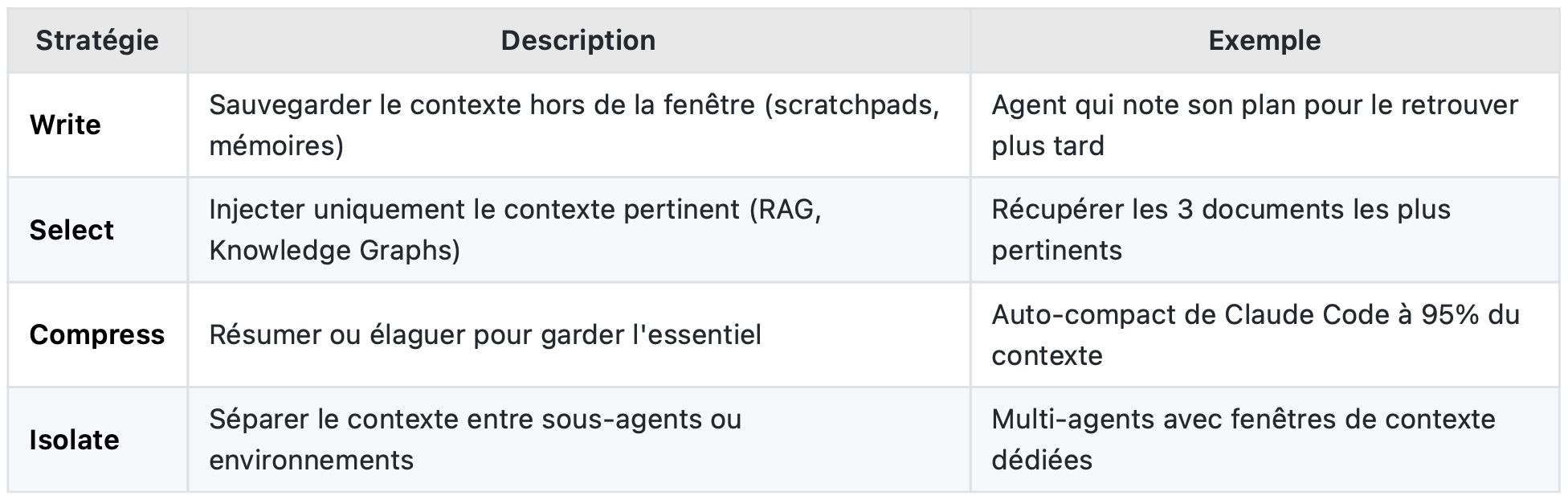
Le Context Engineering est "l'art de fournir au LLM exactement ce dont il a besoin, au bon moment, dans le bon format".
- La connaissance des LLMs est opaque et a une date de coupure (cutoff)
- Au-delà de ~30-40k tokens, les performances chutent drastiquement
- Le contexte mal géré cause : hallucinations, confusions, contradictions
Langchain dans leur documentation en parle très soigneusement, je vous les cite car ils résument pour moi l'essence de la question.
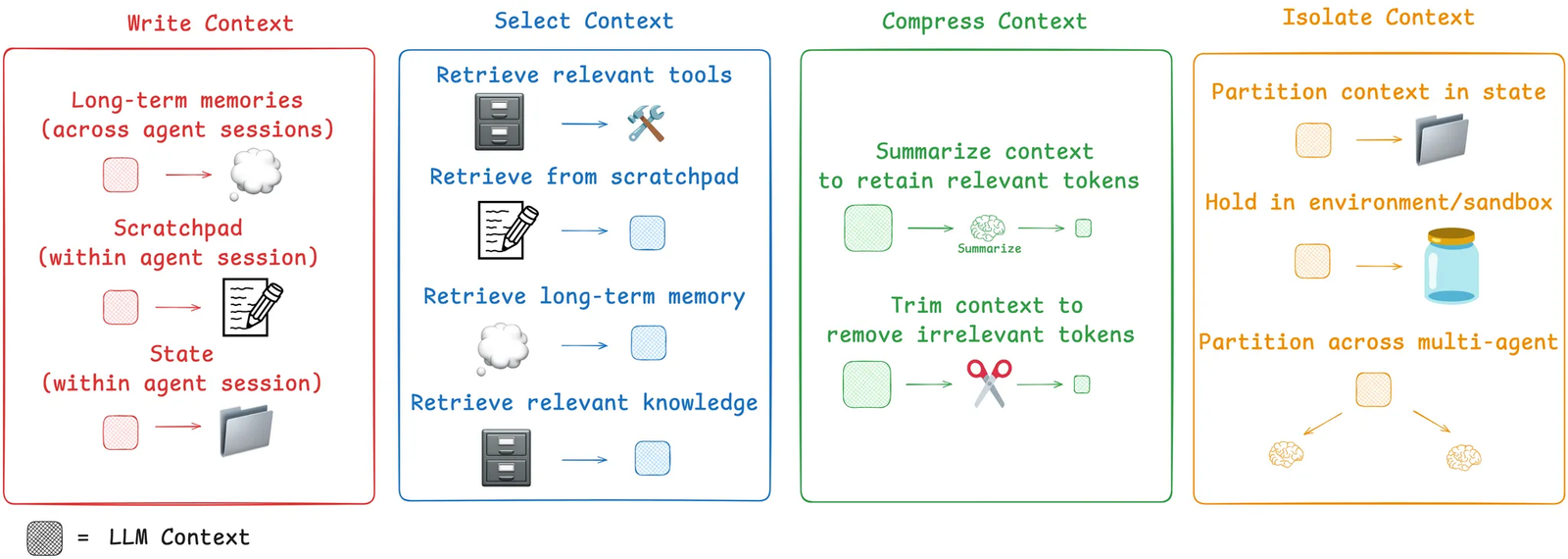
🎯 Les Knowledge Graphs sont des alliés puissants : on ne cherche plus des "morceaux de texte", on navigue dans un réseau de connaissances structurées.
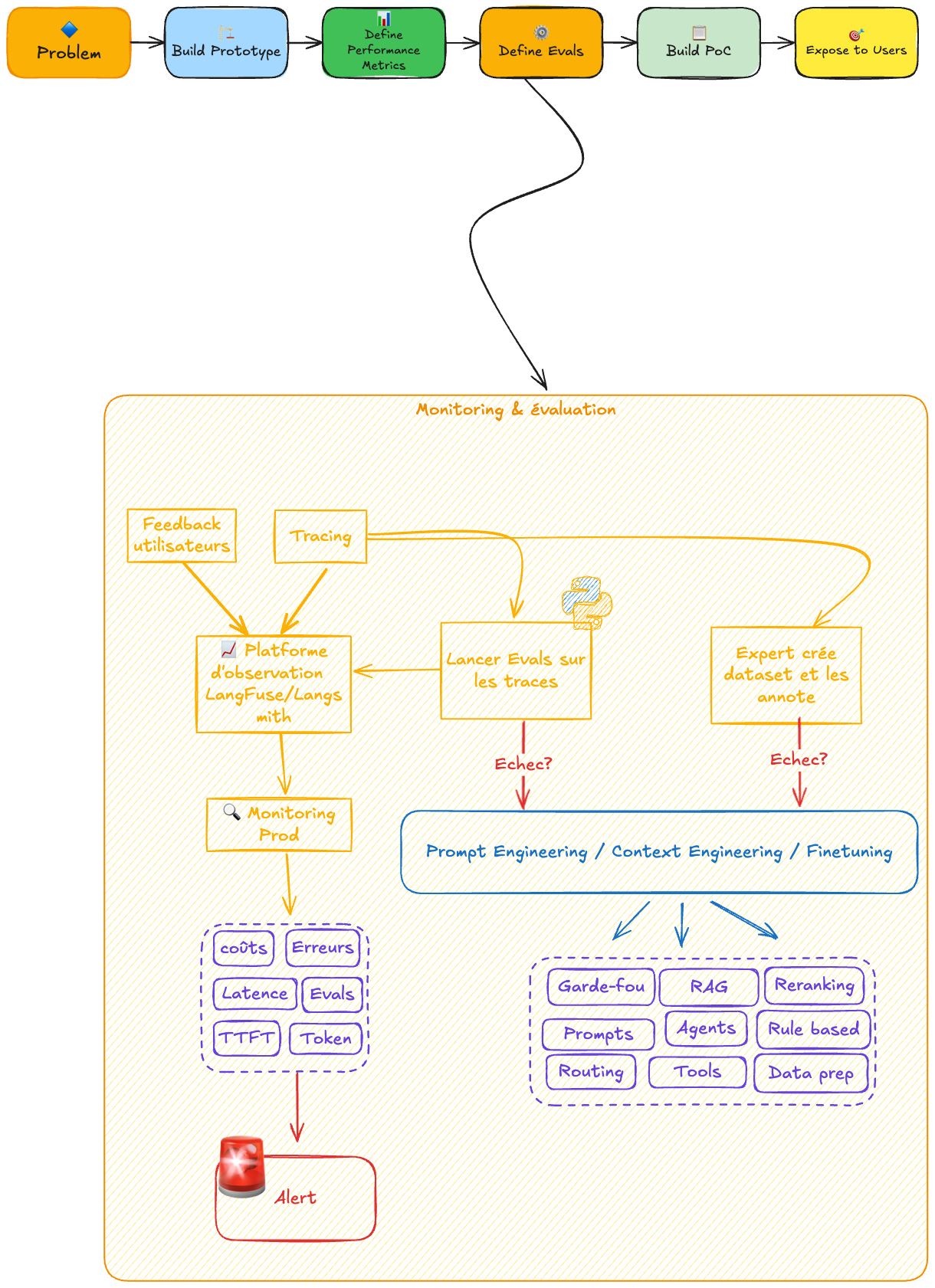
Construire un agent efficace est un processus itératif. Trois principes fondamentaux :
1. Observabilité first — Tracez chaque appel, chaque décision, chaque token consommé
2. Évaluation continue — Mesurez l'impact de chaque modification sur la performance réelle
3. Feedback loop — Récoltez les données d'usage pour affiner continuellement l'agent
[Données/Feedback] → [Analyse] → [Amélioration] → [Test] → [Déploiement] ↺
Sans métriques, vous optimisez à l'aveugle. Sans feedback utilisateur, vous construisez dans le vide.
Voici un paragraphe à ajouter, soit dans une nouvelle section "Pour aller plus loin"**, soit à la fin de **"Monitoring & Eval-Driven Development" :
Une fois votre agent stable en production, l'étape suivante est de fine-tuner le LLM pour vos tâches spécifiques. Un modèle affiné sur vos cas d'usage sera plus performant, plus rapide, et moins coûteux qu'un modèle généraliste.
Le prérequis indispensable : la donnée.Production → Logs & Traces → Feedback utilisateur → Annotations experts → Dataset → Fine-tuning
Cela implique une stratégie de récolte de données à long terme:

💡 Exemple concret : Cognition (Devin) utilise un modèle fine-tuné spécifiquement pour la summarization de contexte — une tâche critique où les modèles généralistes perdent des informations clés.
Le fine-tuning n'est pas un point de départ, c'est une destination. Il nécessite :
- Un agent déjà fonctionnel en production
- Des volumes de données suffisants (centaines à milliers d'exemples)
- Une boucle de feedback bien établie
C'est pourquoi la culture de l'observabilité et de la récolte de feedback doit être intégrée dès le jour 1 — même si le fine-tuning n'arrivera que des mois plus tard. Si jamais il arrive.
Commencez simple. Mesurez. Itérez. La complexité n'est justifiée que par des résultats démontrables.
Ne naviguez pas à l'aveugle. Investissez dans l'observabilité et la récolte de feedback. Et faites en sorte que ce soit une culture du projet car c'est à rendement exponentiel si c'est bien réalisé.
Au contraire, ça peut flinguer tout le projet si c'est mal géré.
Article par B.ERRAJI, consultant data OSSIA - SONATE


Chaque fin de mois, retrouvez une sélection de l'info du monde de l'IT et de la tech !








