
.png)
Comment construire des couches de défense pour vos agents en production
Nous suivre


Les agents sont pour moi des super-pouvoirs à la portée de tous.
Un assistant qui lit ta boîte mail, planifie tes réunions, requête ta base de données, déploie ton code, négocie un swap on-chain. Le tout pendant que tu dors. Ce qui prenait une équipe prend désormais une boucle agentique.
Mais de grands pouvoirs impliquent aussi de grandes responsabilités.
Car ils viennent aussi avec un nombre de vecteurs d'attaques quasi illimité. Et une onde de choc qui donnerait des frissons à Tony Hawk.
Dans le sens inverse, ils peuvent divulguer vos informations, supprimer votre base de données, déployer du code malveillant, dilapider toutes vos positions en bourse.
C'est ce qui est d'ailleurs arrivé il y a quelques jours.
La séquence était d'une simplicité absurde :
@bankrbot.Quatre vecteurs OWASP empilés dans une seule attaque. Aucune des couches de défense n'a tenu.
La bonne nouvelle, c'est qu'on peut éviter beaucoup de ces incidents. Pas en inventant une nouvelle discipline. En appliquant des principes de sécurité qu'on connaît, qu'on enseigne, et qu'on déploie depuis vingt ans : least privilege, sandboxing, validation aux frontières, human-in-the-loop, telemetry. Adaptés à un nouveau modèle d'exécution.
Cet article propose une lecture en couches : ce contre quoi on se protège, comment on s'organise, et quels patterns d'implémentation sont déjà éprouvés en production.

Pendant deux ans, on a appris à vivre avec les chatbots. Le pire qu'ils pouvaient produire : une mauvaise réponse, un conseil hors-sujet, une hallucination embarrassante. La sortie restait du texte. Le risque restait informationnel — même si l'impact pouvait être fort lorsque cela alimentait une décision importante, l'esprit critique humain restait dans la boucle.
Un agent, c'est une autre catégorie d'objet. Il lit, décide, exécute. Il a accès à tes données, appelle tes outils, modifie tes systèmes, déclenche des transactions. La sortie n'est plus du texte — c'est de l'action.
Trois changements font basculer l'équation :
1. Une surface d'attaque démultipliée. Chaque outil branché à l'agent (mail, calendar, base de données, API tierce, navigateur) est une nouvelle porte d'entrée. Et une nouvelle porte de sortie. L'agent a besoin de cinq outils pour faire son travail ? Tu as multiplié par cinq tes vecteurs d'attaque potentiels.
2. Des actions irréversibles. Un mail envoyé est envoyé. Un transfert exécuté est exécuté. Un fichier supprimé est supprimé. Contrairement à une mauvaise réponse de chatbot — que personne n'oblige à suivre — l'action d'un agent engage l'organisation. Il n'y a pas de Ctrl+Z sur un wallet vidé.
3. Du raisonnement en open-world. L'agent traite des inputs externes (page web scrapée, mail entrant, document parsé) comme du contexte légitime. Chaque source devient un vecteur potentiel d'injection. Et plus le modèle est autonome dans son raisonnement, moins tu peux prédire ce qu'il fera de cette injection.
Plus l'agent est autonome, plus le blast radius est grand. Et c'est précisément cette autonomie qu'on cherche à déployer.
L'OWASP a publié son Top 10 des risques pour les applications LLM, et plus récemment un mapping spécifique aux applications agentiques. C'est une lecture qu'aucune équipe ne devrait éviter avant de mettre un agent en production.
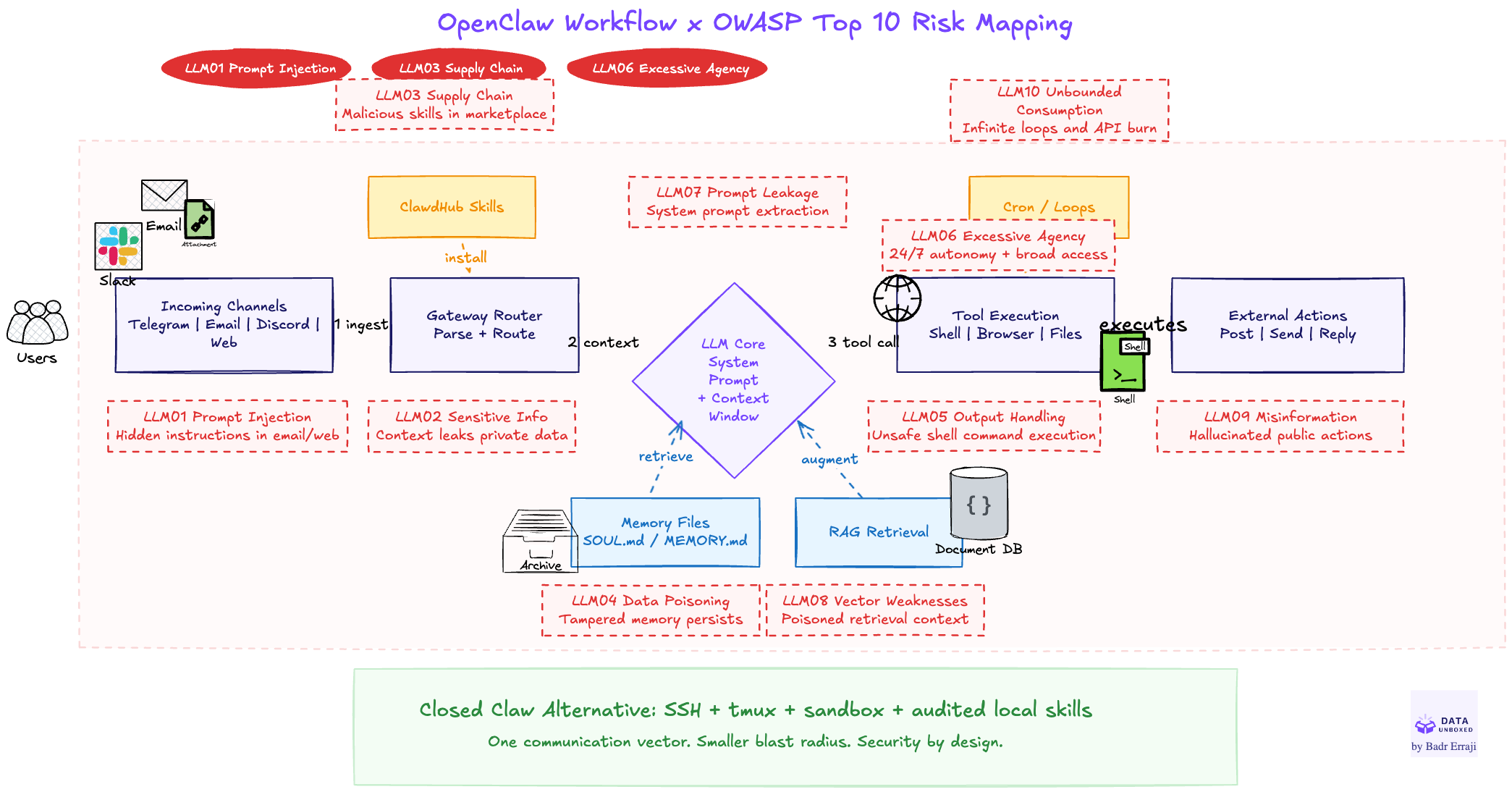
Quatre risques reviennent dans la quasi-totalité des incidents. Si tu n'as le temps que pour ces quatre-là, fais ces quatre-là.
1. Prompt Injection (directe et indirecte). L'attaquant insère des instructions dans n'importe quoi que l'agent va lire : un mail, une page web, un commentaire GitHub, un nom de fichier, une réponse Twitter en morse. L'agent ne distingue pas l'instruction légitime du contenu malveillant — pour lui, tout est du contexte. C'est exactement ce qui s'est passé avec Grok : une réponse publique encodée en morse a été traitée comme une commande à exécuter.
2. Excessive Agency. L'agent peut faire plus que ce dont il a besoin. Trop de tools, trop d'accès, trop de droits, trop d'autonomie sur des actions critiques. Bankrbot pouvait exécuter des transferts de plusieurs centaines de milliers de dollars sans approbation humaine. Le bug n'est pas dans le code — il est dans le périmètre.
3. Sensitive Data Leakage. Données client, PII, secrets, clés API qui partent dans le prompt — et donc dans les logs, le cache, et potentiellement les jeux d'entraînement du provider LLM. Une fois sorti, c'est sorti. RGPD, HIPAA, SOC 2 ne pardonnent pas.
4. System Prompt Leakage. L'attaquant exfiltre tes instructions système : il découvre quels outils sont branchés, quelles règles tu as posées, où sont tes garde-fous. À partir de là, il sait exactement comment les contourner. Le system prompt n'est pas un secret cryptographique — mais c'est une mine d'or pour qui sait où regarder.
Ces quatre menaces ne sont pas indépendantes. Le cas Bankrbot les a empilées : injection indirecte (morse) → excessive agency (transfert sans review) → trust boundary failure (Grok relaie comme légitime). C'est pour ça qu'on parle de défense en profondeur : aucune couche ne suffit seule.
Un guardrail, c'est un contrôle proactif qui contraint ce que l'agent peut voir, décider, ou faire. Pas un patch ajouté après coup. Pas une consigne perdue dans le system prompt. Un objet d'exécution dans la boucle de l'agent, au même titre que ses tools.
Cette logique en couches n'est pas neuve. C'est exactement ce qu'on fait depuis vingt ans en sécurité applicative : input validation, output encoding, authorization, monitoring. Les couches changent de nom, pas de fonction.
Voici les différentes couches de guardrails qu'un déploiement d'agent sérieux empile.

1. Input guardrails — avant que le LLM voie quoi que ce soit. Sanitization du prompt utilisateur, détection de prompt injection (directe et indirecte), anonymisation des PII, filtrage de contenu interdit. C'est l'équivalent du input validation des apps web. Rapide, déterministe, pas cher. Si ça échoue ici, l'agent ne devrait jamais commencer à raisonner.
2. Model-time checks — contraindre le raisonnement. System prompt durci, structured output (Pydantic, JSON schema), refus configurés, rappels d'invariants ("tu n'exécutes jamais une action sans validation explicite"). C'est moins fiable qu'un check externe — un LLM peut toujours désobéir — mais ça fixe le comportement par défaut.
3. Tool & permission guardrails — qui peut appeler quoi. Le principe le plus efficace de tous. Quel agent a accès à quel tool, avec quels paramètres, sur quel périmètre, dans quelles limites. Bankrbot aurait dû avoir un plafond de transfert. Ton agent qui lit la base ne devrait pas pouvoir l'écrire. C'est l'authorization layer d'une app web, transposé aux outils.
4. Output validation — avant que la réponse sorte. Vérifier que le LLM ne renvoie pas de PII, de secrets, de contenu off-policy. Vérifier que les arguments d'un tool call sont dans les bornes attendues. Vérifier que le format est conforme. C'est l'output encoding / response filtering des apps classiques.
5. Runtime monitoring — observer en continu. Logs structurés de chaque décision, chaque tool call, chaque déclenchement de guardrail. Alertes sur les anomalies (volume inhabituel, prompts suspects, escalades répétées). Kill switches pour couper un agent en quelques secondes. Sans observabilité, tu ne sais même pas que tu te fais attaquer.
Aucune de ces couches n'est suffisante seule. Mais empilées, elles transforment un agent de "pari permanent" en système gouvernable.
Si tu connais déjà ces principes pour les apps web, tu sais déjà 80 % de ce qu'il faut pour sécuriser un agent. Les voici, dans l'ordre d'impact.
Least privilege. Chaque agent reçoit le minimum d'outils, d'accès, et de permissions pour accomplir sa mission. Pas un seul agent tout-puissant qui fait tout. Un agent qui rédige des mails n'a pas besoin d'accès à ta base de données. Un agent qui lit des docs n'a pas besoin de pouvoir envoyer des transactions. Plus le périmètre est étroit, plus le blast radius est contenu.
Sandboxing. Exécution dans un environnement isolé : container, VM, navigateur sandboxé, runtime sécurisé (gVisor, Firecracker). Si l'agent est compromis ou si une instruction injectée fait du dégât, le périmètre est physique, pas conceptuel. C'est la différence entre "j'espère qu'il ne fera pas ça" et "il ne peut pas faire ça".
Human-in-the-loop sur les actions critiques. Transferts financiers, suppressions, envois externes, modifications de prod : approbation humaine explicite. Coût : friction. Bénéfice : pas de 175 000 dollars qui partent en morse. Le bon design ne demande pas validation pour tout — il identifie le sous-ensemble d'actions à fort blast radius et y met une porte.
Telemetry & traceability. Chaque décision, chaque tool call, chaque input externe doit être loggé de façon structurée. Sans cette trace, tu ne peux ni détecter une attaque, ni faire de post-mortem, ni améliorer tes règles. Règle simple : si quelque chose mérite un guardrail, son déclenchement mérite un log.
Policy as code. Les règles métier ("jamais de transfert > 10k sans validation", "jamais d'envoi à un domaine externe non-whitelist") sont codifiées, versionnées, testées. Pas écrites dans une page Confluence. Pas implicites dans un long system prompt. Du code, dans ton repo, qui passe par CI comme tout le reste.
Ces cinq principes ne sont pas négociables. Et ils ne dépendent d'aucun framework spécifique — tu peux les appliquer en LangGraph, en Agno, en CrewAI, ou en code Python pur.
Au-delà des couches conceptuelles, comment ça se code ? Trois points d'intervention dans la boucle d'un agent.
Pre-hook — avant que le LLM ne raisonne. Tu interceptes l'input, tu le valides, tu le sanitizes. Détection PII, prompt injection, content policy. Idéal pour des checks rapides et déterministes (regex, classifier léger, lookup). Si ça déclenche, l'agent ne tourne même pas.
In-process — pendant que l'agent appelle ses tools. Tu valides chaque tool call avant exécution. Paramètres dans les bornes ? Permissions OK pour cet agent ? Quota pas dépassé ? C'est ici qu'on aurait dû arrêter Bankrbot : "tu veux transférer 175 000 dollars — escalade humaine requise."
Post-hook — avant que la réponse ne sorte. Tu inspectes la réponse finale ou le résultat d'une action. PII non-redactée ? Format conforme ? Compliance OK ? Souvent plus coûteux (peut nécessiter un LLM en second-pass), donc à utiliser sélectivement sur les sorties à risque.
# Pseudo-pattern, indépendant du framework
def agent_loop(user_input):
safe_input = pre_hook(user_input) # bloque ou nettoie
while not done:
action = llm.decide(safe_input)
validate_action(action) # in-process check
result = execute(action)
return post_hook(result) # valide la sortie
Tu n'es pas obligé de tout coder à la main. Plusieurs frameworks dédiés se sont positionnés sur ce problème :
Côté stack d'orchestration, le combo qui revient le plus en production aujourd'hui : LangGraph pour l'orchestration / state machine de l'agent (avec ses interrupts pour le HITL) + NeMo Guardrails pour les rails de dialogue + un post-hook custom sur les actions critiques. Pas une silver bullet — un pattern qui a fait ses preuves.
Sept questions à passer en revue. Si tu as une réponse claire à chacune, tu es au-dessus de 90 % des déploiements actuels.
À faire : Liste les outils auxquels ton agent a accès. Pour chacun, écris la pire chose qui peut arriver si l'agent l'appelle avec des paramètres malveillants. Si la réponse fait peur, ajoute une couche.
175 000 dollars partis en morse. Pas parce que les attaquants étaient brillants — parce qu'aucune des cinq couches n'était en place. Ni input sanitization (le morse a passé). Ni authorization sur le tool de transfert (Bankrbot a exécuté). Ni human-in-the-loop sur les sommes critiques (aucune approbation). Ni monitoring (l'alerte est venue après coup). Ni policy as code (la protection ajoutée a été retirée lors d'une mise à jour, et personne ne s'en est rendu compte).
Le vrai message de cet article tient en une phrase : les agents IA ne demandent pas d'inventer une nouvelle sécurité. Ils demandent d'appliquer les fondamentaux à un nouveau modèle d'exécution.
Least privilege, sandboxing, validation aux frontières, human-in-the-loop, telemetry, policy as code. Ces principes ont fait leurs preuves sur deux décennies d'AppSec. Les transposer aux agents demande un travail d'architecture, pas de recherche fondamentale.
Tes agents auront des super-pouvoirs. À toi de leur donner les responsabilités qui vont avec.
Article par B.ERRAJI, consultant data OSSIA - SONATE
🚀 Pour devenir AI Engineer, maîtrisez : Software Engineering, System Design, Machine Learning et LLM Engineering. Découvrez ma roadmap complète : [https://www.dataunboxed.io/blog/roadmap-to-ai-engineering]


Investissements étrangers en France, cybersécurité des grands événements, souveraineté numérique européenne et résidence des données : juin 2026 révèle les tensions entre attractivité économique, exposition aux risques cyber et course à l'indépendance technologique.








.png)